FlowStorm is a tracing debugger for Clojure and ClojureScript.
It can instrument any Clojure code and provides many tools to explore and analyze your programs executions.
1. Quick start
Before you start check FlowStorm minimum requirements.
|
Important
|
Minimum requirements
|
1.1. Clojure
There are two ways of using FlowStorm for Clojure :
-
With ClojureStorm (recommended) : Swap your Clojure compiler at dev time by ClojureStorm and get everything instrumented automatically
-
Vanilla FlowStorm : Just add FlowStorm to your dev classpath and instrument by tagging and re-evaluating forms
1.1.1. ClojureStorm
This is the newest and simplest way of using FlowStorm. It requires you to swap your official Clojure compiler by ClojureStorm only at dev time.
Swapping compilers sounds like a lot, but don’t worry, ClojureStorm is just a patch applied over the official compiler with some extra stuff for automatic instrumentation. You shouldn’t encounter any differences, it is only for dev, and you can swap it back and forth by starting your repl with a different alias or lein profile.
The easiest way to run and learn FlowStorm with ClojureStorm is by running the repl tutorial.
Try it with no project and no config
You can start a repl with FlowStorm with a single command like this :
;; on Linux and OSX
clj -Sforce -Sdeps '{:deps {} :aliases {:dev {:classpath-overrides {org.clojure/clojure nil} :extra-deps {com.github.flow-storm/clojure {:mvn/version "1.13.0-alpha4"} com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}}}' -A:dev
;; on Windows
clj -Sforce -Sdeps '{:deps {} :aliases {:dev {:classpath-overrides {org.clojure/clojure nil} :extra-deps {com.github.flow-storm/clojure {:mvn/version """1.13.0-alpha4"""} com.github.flow-storm/flow-storm-dbg {:mvn/version """4.7.0"""}}}}}' -A:devPasting that command on your terminal will bring up a repl with FlowStorm and the compiler swapped by ClojureStorm. When the repl comes up
evaluate the :dbg keyword to bring up the UI and then click on Help→Tutorial on the menu for a tour of the basics.
After the tutorial you may want to use it on your projects. You use it by adding a deps.edn alias or lein profile.
The simplest way is to setup it globally, so that is what we are going to do next. You can also add it only to specific projects if they require special configurations.
Global setup as deps.edn aliases
You can setup your global ~/.clojure/deps.edn (on linux and macOS) or %USERPROFILE%\.clojure\deps.edn (on windows) like this :
{...
:aliases
{:1.12-storm {:classpath-overrides {org.clojure/clojure nil}
:extra-deps {com.github.flow-storm/clojure {:mvn/version "1.13.0-alpha4"}
com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}
;; Optional plugins you find yourself using regularly
:fs-web-plugin {:extra-deps {com.github.flow-storm/flow-storm-web-plugin {:mvn/version "1.0.0-beta"}}
:jvm-opts ["-Dclojure.storm.instrumentOnlyPrefixes.webPlugin=org.httpkit.server,ring.adapter.jetty,next.jdbc.result-set"
"-Dflowstorm.plugins.namespaces.webPlugin=flow-storm.plugins.web.all"]}
...}}Then you can start your repls with the :1.12-storm alias (like clj -A:1.12-storm). When the repl comes up evaluate the :dbg keyword to bring up the UI,
then click on Help→Tutorial on the menu for a tour of the basics.
Global setup as leiningen profiles
You can setup your global ~/.lein/profiles.clj (on linux and macOS) or %USERPROFILE%\.lein\profiles.clj (on windows) like this :
{:1.12-storm
{:dependencies [[com.github.flow-storm/clojure "1.13.0-alpha4"]
[com.github.flow-storm/flow-storm-dbg "4.7.0"]]
:exclusions [org.clojure/clojure]}
;; Optional plugins you find yourself using regularly
:fs-web-plugin
{:dependencies [[com.github.flow-storm/flow-storm-web-plugin "1.0.0-beta"]]
:jvm-opts ["-Dclojure.storm.instrumentOnlyPrefixes.webPlugin=org.httpkit.server,ring.adapter.jetty,next.jdbc.result-set"
"-Dflowstorm.plugins.namespaces.webPlugin=flow-storm.plugins.web.all"]}
...}Then you can start your project repls with +1.12-storm profile (like lein with-profile +1.12-storm repl). When the repl comes up evaluate the :dbg keyword to bring up the UI,
then click on Help→Tutorial on the menu for a tour of the basics.
|
Note
|
Running lein repl without a project
For some reason if you run |
Per project setup with deps.edn
If your project is using deps.edn, you can add an alias that looks like this :
{...
:aliases {:1.12-storm
{;; for disabling the official compiler
:classpath-overrides {org.clojure/clojure nil}
:extra-deps {com.github.flow-storm/clojure {:mvn/version "1.13.0-alpha4"}
com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}}}Once you have setup your deps.edn, start your repl with the :1.12-storm alias and run the debugger by evaluating
the :dbg keyworkd on your repl (this means just type :dbg and hit return).
If it is your first time using FlowStorm, when the UI comes up click on Help→Tutorial on the menu for a tour of the basics.
If you need more fine control over instrumentation see controlling instrumentation.
Setup with leiningen
If your project uses lein, you can add a profile that looks like this :
(defproject my.project "1.0.0"
:profiles {:1.12-storm
{:dependencies [[com.github.flow-storm/clojure "1.13.0-alpha4"]
[com.github.flow-storm/flow-storm-dbg "4.7.0"]]
:exclusions [org.clojure/clojure]}}
...)Once you have setup your lein profile globally or per project, start your repl with the 1.12-storm profile and run the debugger by evaluating
the :dbg keyworkd on your repl (this means just type :dbg and hit return).
Make sure you activate the profile with lein with-profile +1.12-storm repl.
If it is your first time using FlowStorm, when the UI comes up click on Help→Tutorial on the menu for a tour of the basics.
If you need more fine control over instrumentation see controlling instrumentation.
|
Note
|
lein dependencies
If you are using lein < 2.11.0 make sure your global :dependencies don’t include the official org.clojure/clojure dependency. Moving to lein latest version should work ok even if your global :dependencies contains the Clojure dep. |
1.1.2. Vanilla FlowStorm
If you use the clojure cli you can start a repl with the FlowStorm dependency loaded like this :
;; on Linux and OSX
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}'
;; on Windows
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version """4.7.0"""}}}'If you are a lein user add the dependency to your project.clj :dependencies and run lein repl.
Then require the api namespace and start the debugger :
user> (require '[flow-storm.api :as fs-api]) ;; the only namespace you need to require
user> (fs-api/local-connect) ;; will run the debugger GUI and get everything readyYou should now see a empty debugger window. Click on the recording button to leave the debugger in recording mode and the let’s debug something:
user> #rtrace (reduce + (map inc (range 10))) ;; #rtrace will instrument and run some codeAfter running it, you should get the return value of the expression (as if #rtrace wasn’t there), but now you will also have the debugger UI showing your recordings.
From here you probably want to check out the Flows tool which contains a lot of information about exploring your recordings.
1.2. ClojureScript
Debugging ClojureScript is a case of remote debugging in FlowStorm. This means the debugger will run in a separate process and connect to the debuggee (your browser or nodejs runtime) via a websocket and optionally an nrepl server.
There are two ways of using FlowStorm with ClojureScript :
-
With ClojureScriptStorm (recommended) : Swap your ClojureScript compiler by ClojureScriptStorm at dev and get everything instrumented automatically
-
Vanilla FlowStorm : Just add FlowStorm to your dev classpath and instrument by tagging and re-evaluating forms
ClojureScriptStorm is a fork of the official ClojureScript compiler that adds automatic instrumentation so you don’t need to think about it (you can still disable it when you don’t need it).
You use it by swapping the official ClojureScript compiler by ClojureScriptStorm at dev time, using dev aliases or profiles.
|
Note
|
Repl connection
For enabling every debugger feature, FlowStorm needs to connect to a cljs repl. Currently only shadow-cljs repl over nrepl is supported. |
1.2.1. ClojureScriptStorm with shadow-cljs
|
Important
|
Minimum requirements
|
For setting up FlowStorm with shadow-cljs you need to modify two files, your shadow-cljs.edn and your deps.edn.
This is setup once and forget, so once you have configured FlowStorm you can do everything from the UI, without
any other sources modifications.
If you want a shadow-cljs template to play with, take a look at this repo.
|
Note
|
shadow-cljs
Currently you can only use ClojureScriptStorm with shadow-cljs if you are resolving your
dependencies with deps.edn. This means having |
First, make your shadow-cljs.edn looks something like this :
{:deps {:aliases [:1.12-cljs-storm]}
:nrepl {:port 9000}
...
:builds
{:my-app {...
:devtools {:preloads [flow-storm.storm-preload]
:http-port 8021}}}}So, the important parts are: you need to tell shadow to apply your deps.edn :1.12-cljs-storm alias, set up a nrepl port,
and also add flow-storm.storm-preload to your preloads. If you have other preloads make sure flow-storm.storm-preload
is the first one.
Then, modify your deps.edn dev profile to look like this :
{...
:aliases
;; this alias can be defined globally in your ~/.clojure/deps.edn so you don't have to modify this file in your project
{:1.12-cljs-storm
{:classpath-overrides {org.clojure/clojurescript nil} ;; disable the official compiler
:extra-deps {thheller/shadow-cljs {:mvn/version "3.4.11"
:exclusions [org.clojure/clojurescript]}
;; bring ClojureScriptStorm
com.github.flow-storm/clojurescript {:mvn/version "1.12.145-1"}
;; add FlowStorm runtime dep
com.github.flow-storm/flow-storm-inst {:mvn/version "4.7.0"}}}}}There are lots of things going on there, but the main ones are: disabling the official compiler, adding ClojureScriptStorm and FlowStorm dependencies, and then configuring what you want ClojureScriptStorm to automatically instrument.
By default the JVM property cljs.storm.instrumentAutoPrefixes is true so all your project top level namespaces
will be instrumented automatically.
If you need to set that property to false it is important to configure what namespaces you want to instrument,
and you do this by setting the cljs.storm.instrumentOnlyPrefixes jvm property.
This is a comma separated list of namespaces prefixes, you normally want your app namespaces plus some libraries, like :
cljs.storm.instrumentOnlyPrefixes=org.my-app,org.my-lib,hiccup
And this is it. Once you have it configured, run your shadow watch as you normally do, load your app on the browser (or nodejs).
Whenever your need the debugger, on a terminal run the ui with your shadow-cljs.edn data :
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debugger :port 9000 :repl-type :shadow :build-id :my-appand then reload you page so it connects to it.
Since we started the app with flowstorm.startRecording=false you will have to click on the record button once to start recording.
Whenever recording is enable and something executes under an instrumented namespace you should see the recordings appear in the debugger
under the main thread.
|
Note
|
recording expressions typed on the repl
If you type at the repl something like |
1.2.2. ClojureScriptStorm with cljs.main
You can use FlowStorm and ClojureScriptStorm with cljs.main.
The easiest way to try it is just by starting a repl, like this :
clj -Sforce -J-Dcljs.storm.instrumentOnlyPrefixes=cljs.user -Sdeps '{:deps {com.github.flow-storm/clojurescript {:mvn/version "1.12.145-1"} com.github.flow-storm/flow-storm-inst {:mvn/version "4.7.0"}}}' -M -m cljs.main -co '{:preloads [flow-storm.storm-preload]}' --replIf you run the command above you are running cljs.main --repl which will start a ClojureScript repl on
your terminal and open a browser connected to it. You runtime will also start with FlowStorm preloaded and everything under cljs.user
is going to be instrumented.
Then on a different terminal run the FlowStorm UI :
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debuggerAnd now refresh your browser page so your browser app connects to the UI.
|
Note
|
Limitations
There are some small limitations like not being able to modify instrumentation from the UI without restarting the repl. This is because the FlowStorm UI needs to also connect via nrepl to JVM process running the compiler, which isn’t available when running cljs.main. |
1.2.3. ClojureScript vanilla FlowStorm
|
Note
|
Async/await limitations
ClojureScript with vanilla FlowStorm doesn’t currently support async/await introduced in ClojureScript 1.12.145 If you need async/await support you can use it with ClojureScriptStorm as described above or otherwise open an issue. |
Let’s say you are using shadow-cljs to start a ClojureScript repl.
First you need to add FlowStorm dependency to your project dependencies, like this :
$ cat shadow-cljs.edn
{...
:dependencies [... [com.github.flow-storm/flow-storm-inst "4.7.0"]]
;; the next two lines aren't needed but pretty convenient
:nrepl {:port 9000}
:my-build-id {:devtools {:preloads [flow-storm.preload]}}
...}Then let’s say you start your repl like :
npx shadow-cljs watch :my-build-id
shadow-cljs - config: /home/jmonetta/demo/shadow-cljs.edn
shadow-cljs - server version: 2.19.0 running at http://localhost:9630
shadow-cljs - nREPL server started on port 9000
shadow-cljs - watching build :my-build-id
[:my-build-id] Configuring build.
[:my-build-id] Compiling ...
[:my-build-id] Build completed. (127 files, 0 compiled, 0 warnings, 6.19s)
cljs.user=>As you can see from the output log shadow-cljs started a nrepl server on port 9000, this is the port FlowStorm needs to connect to, so to start the debugger and connect to it you run :
;; on linux and mac-os
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debugger :port 9000 :repl-type :shadow :build-id :my-build-id
;; on windows
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version """4.7.0"""}}}' -X flow-storm.debugger.main/start-debugger :port 9000 :repl-type :shadow :build-id :my-build-idAnd that is all you need, the debugger GUI will pop up and everything will be ready.
Try tracing some code from the repl :
cljs.user> #rtrace (reduce + (map inc (range 10))) ;; #rtrace will instrument and run some codeAfter running it, you should get the return value of the expression (as if #rtrace wasn’t there).
The debugger thread list (the one on the left) shows all the threads it has recordings for. Because we are
in javascript land there will always be just one thread, called main.
Double clicking it should open the "thread exploring tools" for that thread in a new tab.
This guide will cover all the tools in more detail but if you are interested in code stepping for example you will find
it in the code stepping tool at the bottom left corner of the thread tab, the one that has the () icon.
Click on it and use the stepping controls to step over the code.
Now that everything seems to be working move on and explore the many features FlowStorm provides. There are many ways of instrumenting your code, and many ways to explore its executions.
If you are not using a repl or the repl you are using isn’t supported by FlowStorm yet you can still use the debugger but not all features will be supported (mainly the browser features).
For this you can start the debugger like before but without any parameters, like this :
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debuggerAnd then go to your app code and call (flow-storm.runtime.debuggers-api/remote-connect) maybe on your main, so every time your program starts
will automatically connect to the repl.
|
Note
|
ClojureScript environments
FlowStorm is supported for ClojureScript in :
|
|
Note
|
NodeJs and react-native
On NodeJs and react-native you need to install the For react-native if your app is running inside a cellphone you will have to also provide the |
|
Note
|
App initialization debugging
If you need to debug some app initialization, for adding |
Here is a repo you can use if you want to try FlowStorm with shadow-cljs https://github.com/flow-storm/shadow-flow-storm-basic
1.2.4. Multiple ClojureScript builds
You can setup FlowStorm to debug multiple ClojureScript builds. This can be useful when your application is made up of multiple parts, like when you have web workers.
Debugging multiple builds require multiple debugger instances, one per build.
The FlowStorm UI will start a websocket server, by default on 7722, so if you want to run multiple instances of it, you need
to run each instance under a different port. You can do this by providing a :ws-port to the startup command.
So let’s say you want to run two debuggers, one for your page and one for a webworker, your can run them like this :
# on one terminal start your app debugger instance
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debugger :port 9000 :repl-type :shadow :build-id :my-app :ws-port 7722
# on a second terminal start your webworker debugger instance
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debugger :port 9000 :repl-type :shadow :build-id :my-web-worker :ws-port 7733Now you also need to configure your builds to tell them what port they should connect to.
You do this by writing different preloads for each of your builds, and then using them instead of your flow-storm.storm-preload, like:
my_app.main_storm_preload.cljs
(ns my-app.main-storm-preload
(:require [cljs.storm.tracer]
[flow-storm.tracer :as tracer]
[flow-storm.runtime.debuggers-api :as dbg-api]))
(dbg-api/start-runtime)
(tracer/hook-clojurescript-storm)
(dbg-api/remote-connect {:debugger-host "localhost" :debugger-ws-port 7722})my_app.webworker_storm_preload.cljs
(ns my-app.webworker-storm-preload
(:require [cljs.storm.tracer]
[flow-storm.tracer :as tracer]
[flow-storm.runtime.debuggers-api :as dbg-api]))
(dbg-api/start-runtime)
(tracer/hook-clojurescript-storm)
(dbg-api/remote-connect {:debugger-host "localhost" :debugger-ws-port 7733})They are the same as flow-storm.storm-preload just with different port numbers.
Now you can configure your shadow-cljs.edn like this :
{...
:builds
{:app
{:target :browser
...
:modules
{:my-app {:init-fn my.app/init
:preloads [my-app.main-storm-preload]}
:my-webworker {:init-fn my.app.worker/init
:preloads [my-app.webworker-storm-preload]
:web-worker true}}}}}|
Note
|
Multiple debuggers tips
You can change the theme or customize the styles of different instances to make it easier to know which debugger instance is connected to which application. |
1.3. Babashka
You can debug your babashka scripts with FlowStorm using the JVM. The process is quite simple.
Let’s say we want to debug this example script https://raw.githubusercontent.com/babashka/babashka/master/examples/htmx_todoapp.clj which runs a webserver with a basic todo app.
First we need to generate a deps.edn by running bb print-deps > deps.edn
Then modify the resulting deps.edn to add the FlowStorm alias like this :
{...
:aliases {:dev {:classpath-overrides {org.clojure/clojure nil} ;; for disabling the official compiler
:extra-deps {com.github.flow-storm/clojure {:mvn/version "1.13.0-alpha4"}
com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}
:jvm-opts ["-Dclojure.storm.instrumentOnlyPrefixes=user"]}}}With clojure.storm.instrumentOnlyPrefixes=user we are telling ClojureStorm to instrument everything inside
the user namespace since the script doesn’t contain any namespace declaration.
And that is it, you can now start your clojure repl as usual, with clj -A:dev and then eval the :dbg keyword to
start the debugger UI.
Then eval the entire file to compile everything. To start the server in this example you will have to remove the wrapping that is basically only allowing the server to run if we are running from babashka, like this :
(when true #_(= *file* (System/getProperty "babashka.file"))
...)so we can also start it from Clojure.
After the server has started, you can use the app from the browser and everything will get recorded as usual.
2. The tool bar
The toolbar as well as the menu provides quick access to some general commands.
From left to right:
-
Cancel current running task. Whenever you a running a task that can take some time, this button will be red, and you can use it to cancel the task.
-
The
Inst enablebutton allows to enable/disable instrumentation when in a Storm environment. A change on instrumentation will only affect newly compiled code.
3. Flows tool
The Flows vertical tab contains a bunch of tools for recording and analyzing your programs executions.
First of all, what are Flows?
A Flow is an "execution flow" recording unit. The only purpose of a flow is to group recording activity.
This grouping allows us for example to run some code and record it under flow-0, then modify our code, run it again, and
record this second run (or flow) under flow-1. Now we can access both recordings separately.

When you first open FlowStorm UI you will see four things, from left to right :
-
Clear your recordings if any.
-
Start/Stop recording. You can keep your heap from growing by stopping recording when you don’t need it.
-
Start/Stop recording the multi-thread timeline. Check out the multi-thread timeline tool.
-
The
Rec oncombo-box to select under what flow new recordings are going to be stored.
Whenever there is something recorded for a flow, a new tab with the flow name will appear.
Execution inside a flow will be grouped by threads. So the first thing you will see on a flow is a menu of threads we have recordings for so far. This threads will be referred sometimes as timelines, since they are a sequence of recorded execution steps.
Let’s say for example we have selected to record under flow-1 and run some multi threaded code.
We are going to see something like this :
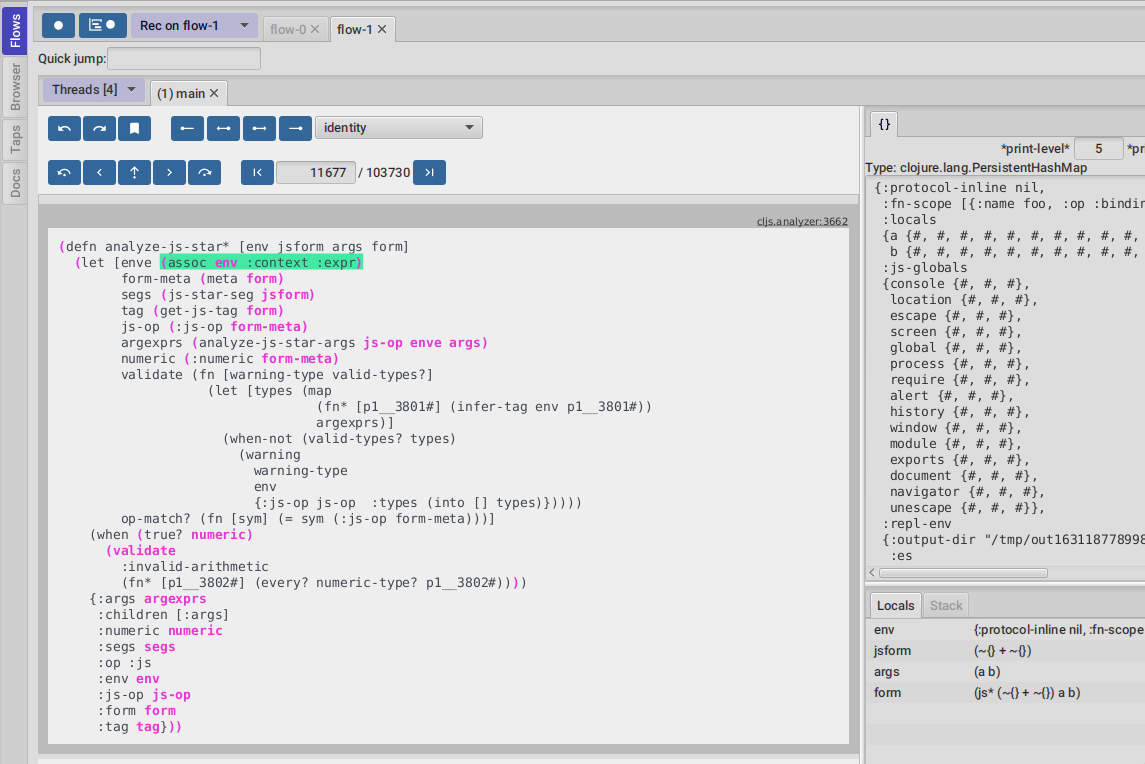
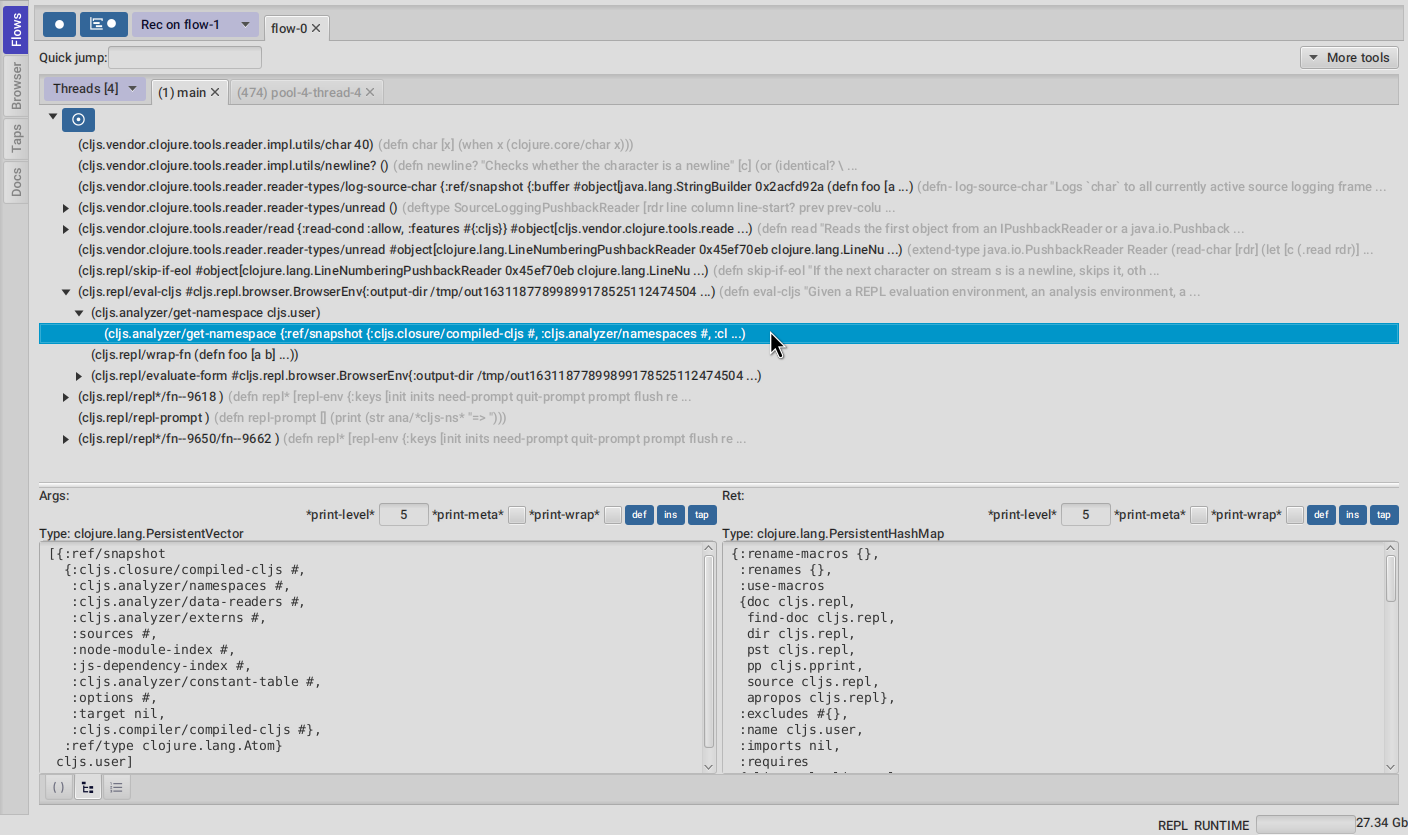
There is a lot going on in the screenshot above, but the most important are :
-
we have configured FlowStorm to record new executions under
flow-1 -
we have recorded stuff under
flow-1and there are also some previous recordings underflow-0 -
we are currently looking at
flow-1, we have opened to explore the thread with id1calledmainand we are exploring it in the code stepper -
Threads [4]indicates we have recorded activity in 4 threads, which we can access via this menu
Now for a different example :
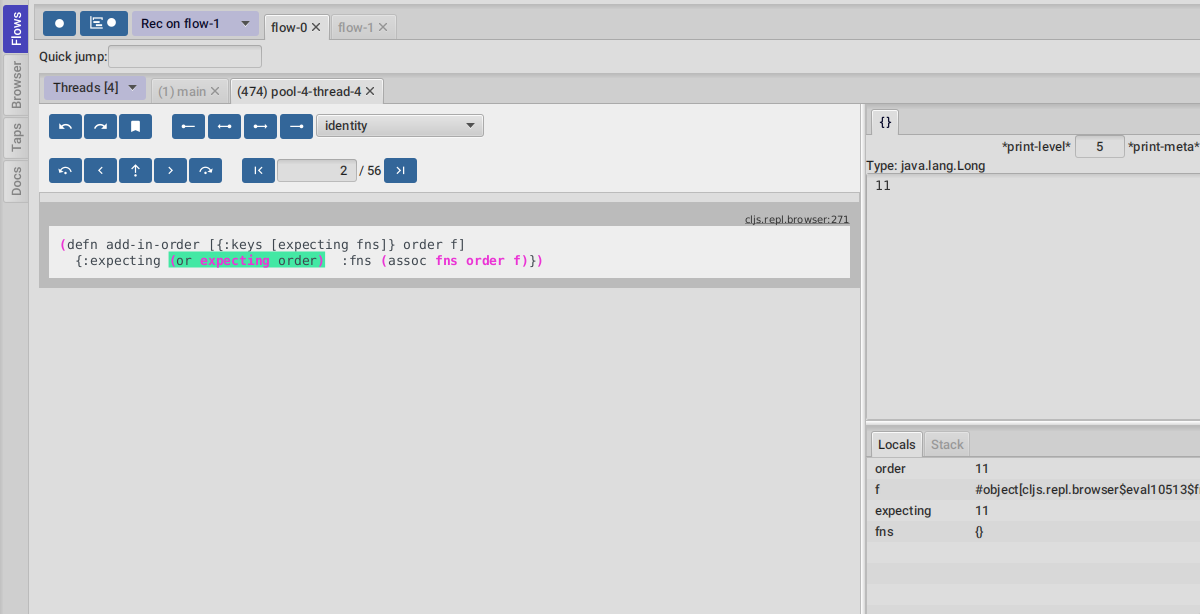
This second image shows us exploring the recordings of a thread with id 474, called pool-4-thread-4 on flow-0.

The Flows tool also contains a toolbar that contains the Quick jump box.
Use it for quickly opening the first recording of a function in the code stepper.
Will autocomplete the first 25 matches.
In the screenshot above we see analyzing the recordings in the code stepper but there are many tools to explore the recorded timelines, which we are going to describe next.
3.1. Code tool
The code tool is the first of the Flows tab. It provides most of the functionality found in a traditional debugger.
You can use it to step over each expression, visualize values, locals and more.
3.1.1. Code stepping
The code tool allows you to step and "travel throught time" in two ways:
-
Use the controls at the top to step over your code in different ways.
-
Click on the highlighted forms to position the debugger at that point in time.
For moving around using the controls we have two rows of buttons.
The second row of controls, the most important one, are the stepping controls.
From left to right they are :
-
Step over backwards, will make one step backwards always staying on the same frame.
-
Step backwards, will step backwards in time going into sub functions.
-
Step out, will position the debugger in the next step after this function was called.
-
Step forward, will step forward in time going into sub functions.
-
Step over forward, will make one step forwards always staying on the same frame.
The numbers at the center show current_step_index / total_steps. This means that a total of total_steps has been recorded
for this thread so far. Write any number (less than total_steps) on the text box to jump into that position in time.
The buttons around the step counter are :
-
Jump to the first step of the recording.
-
Jump to the last step of the recording.
On the first row we have more controls, also for moving around in time.
From left to right we have :
-
Undo navigation
-
Redo navigation
-
Add a bookmark
-
The last stepping controls to the right are the power stepping controls.
|
Note
|
Highlighting
Only the forms that were executed at least once for the current function frame will be highlighted. |
This means that code can be un-highlighted for two reasons:
-
there isn’t any recording for that part of the code
-
there is a recording but doesn’t belong to this function frame.

In the contrived example above we see we are stepping the foo function. All inside this function
body is highlighted but the bodies of the two anonymous functions for mapping and reducing. This
will only get highlighted once you step into their bodies.
In this case you are sure there are recordings for these functions bodies because the reduce is non lazy, so if you keep stepping eventually you will get into their bodies, but there is a faster way.
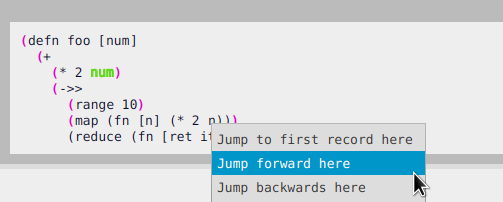
For this you can right click on any un-highlighted expression that you think there could be a recording for and
select Jump forward here.
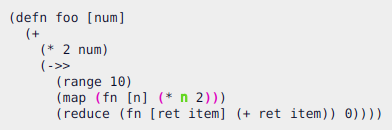
This will make FlowStorm scan from the current point of the timeline searching forward for a value recorded at that coordinate (if any) and move the stepper to that point in time.
You also have Jump to first record here which will scan from the beginning of the timeline and Jump backwards here
which will search backwards from the current position.
3.1.2. Power stepping

The controls at the right are power stepping controls. They provide more powerfull ways of stepping through the code.
Clicking on the first, back, next or last buttons will navigate the timeline using the selected power stepping tool in the dropdown.
There are currently six power stepping tools :
-
identity, will step to the prev/next value which identity is the same as the current value. -
'equality', will step to the prev/next value which is equals (clojure equality) to the current value.
-
same-coordwill step to the prev/next value for the same coordinate. This means it will move to the next recording in the timeline for this exact place in the code you are currently in. You can also see it as take me to all the situations when the current expression executed doesn’t matter how we got to it. -
same-fn-framewill step to the prev/next expression on the same function call frame (keep me on this function) -
custom, allows you to provide a predicate, which will be used to find the next step. If you define it like(fn [v] (map? v))will make the power stepper step over all map values. -
custom-same-coord, the same ascustombut fixed on the current coordinate likesame-coord. -
identity-other-thread, will step to a position which identity is the same as the current value in a different thread. Here the prev and next arrows do the same thing, it will just jump to the first position that matches this value on a different thread. This has some limitations. If there are more than two threads working with this identity there is no way of choosing which thread to go. If you need more control, checkout the programmable debugging section, specially thefind-expr-entryfunction. -
fn-call, allows you to provide a function to step to.
|
Note
|
Custom stepping
Custom power stepping is only supported in Clojure now. |
Power stepping automatically skips all values equals to :flow-storm.power-step/skip. This can be useful when combined
with snapshot-value as a way of ignoring some of them, which provides a way of sampling
tight loops like in games.
3.1.3. Searching
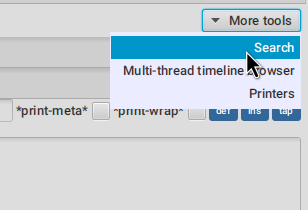
You can use the search tool to search over all your flow recorded expressions and then make the stepper jump to them.
You can find the search tool under More tools → Search.
There are multiple ways of searching:
-
By pr-str
-
By data window current value
-
By predicate
Searching by pr-str
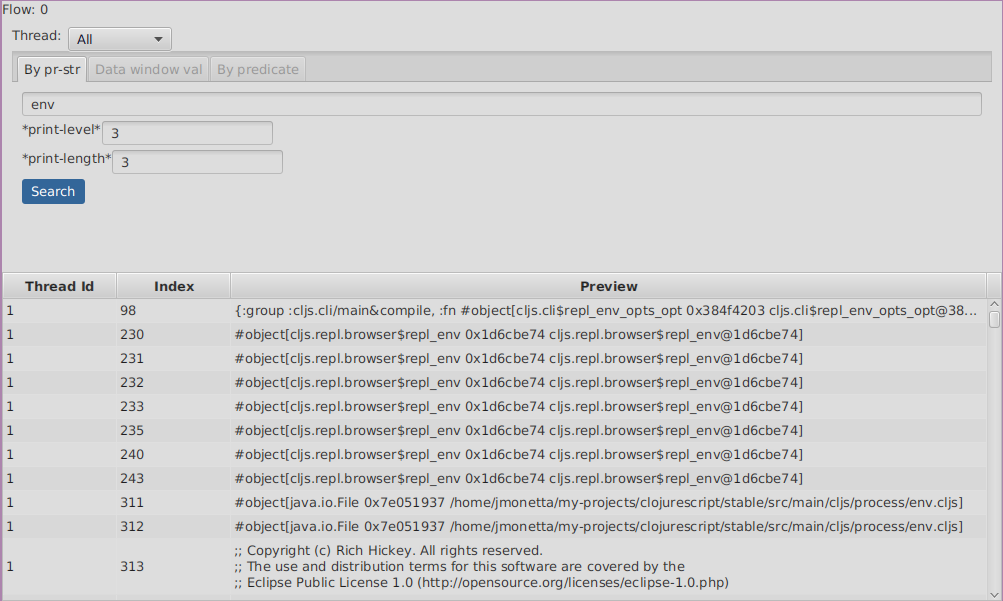
This type of search will walk over the selected threads expressions, converting their values to strings with pr-str up to the selected level and depth
and then checking if the resulting string contains your provided query string.
Searching by DataWindow value
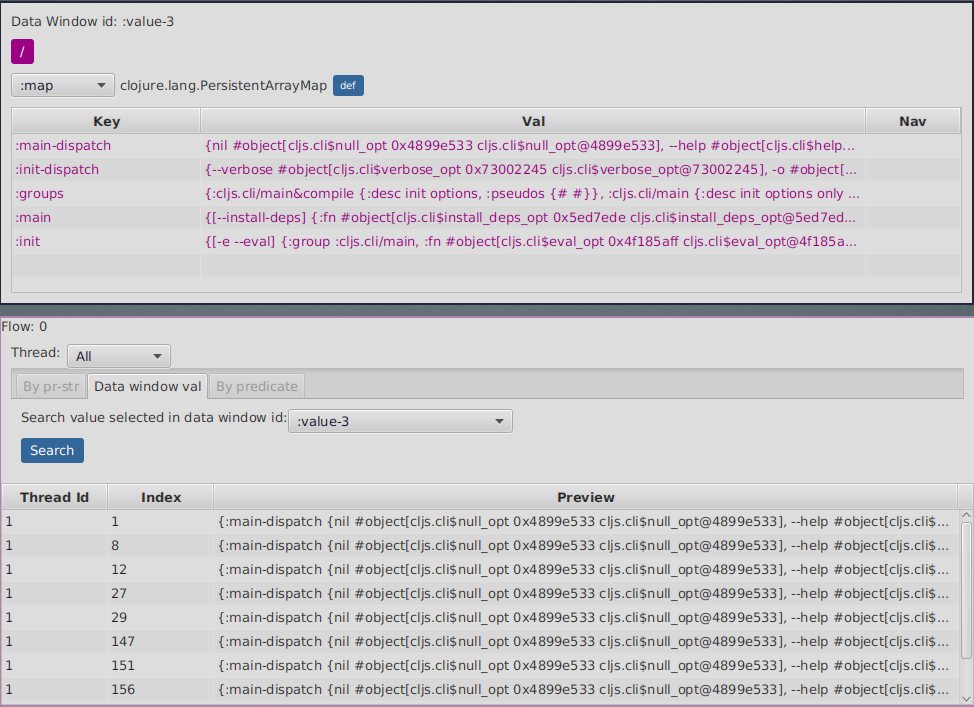
Searching by data window value allows you to select any of the current data windows and will search for the current selected data window value over the selected threads expressions values using identity.
Searching by predicate
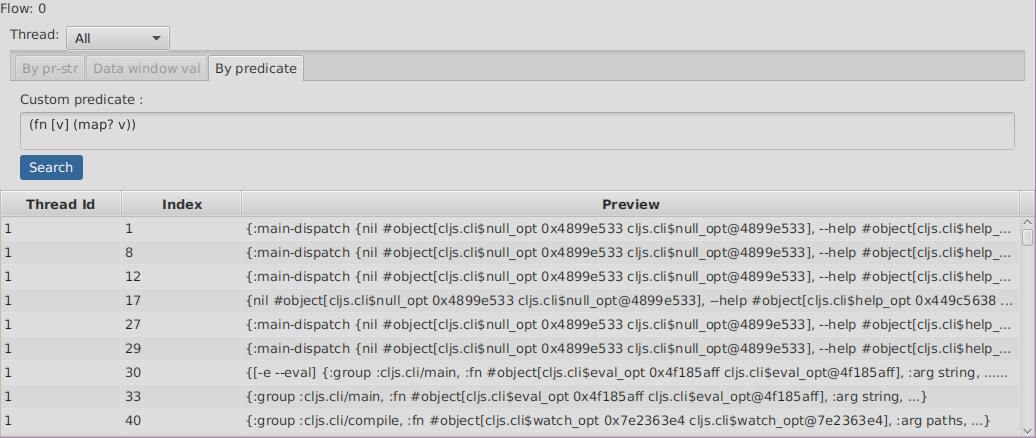
Searching by predicate allows you to provide a Clojure predicate which will be used over all selected threads expressions values.
3.1.4. Loops
Whenever you click a highlighted form that has been executed multiple times inside the same function call (any kind of loop), instead of immediately jumping into it, FlowStorm will popup a menu, like in the picture below :
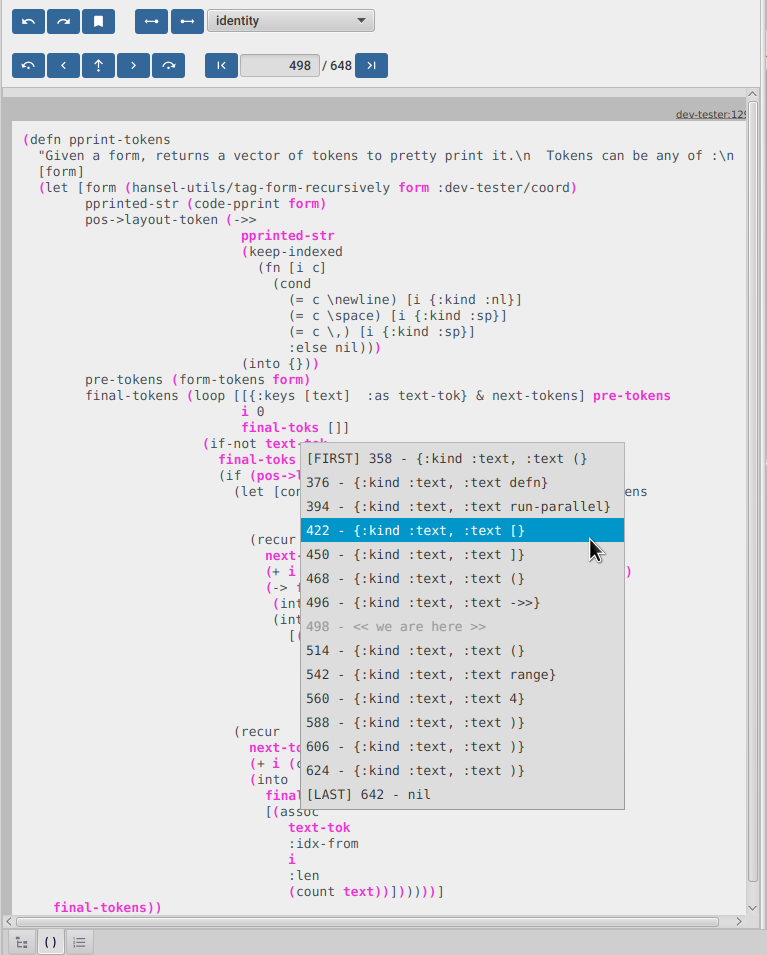
This is the loops navigation menu. It allows you to quickly move around interesting iterations of the loop.
The menu will display slightly different options depending on you current position. The [FIRST] … and [LAST] …
entries will always show, which allows you to quickly jump to the first and last iteration of the loop.
If you are currently before the loop, clicking into any expression inside the loop will show the first 20 values for the clicked expression.
If instead you are currently in a expression after the loop, clicking back to an expression inside the loop, will show the last 20 values for the clicked expression.
Now if you are currently stepping inside the loop, clicking any other expression inside it will show you 10 values before and 10 values after of your current position.
Clicking on any of this entries will take you to that position in time.
If this is not enough, and you want to see all the values taken by some expression along the loop, you can always use the printer tool.
3.1.5. Exceptions debugging
FlowStorm will capture all functions that didn’t return because an exception unwind the stack, even
when that exception was captured further and it didn’t bubble up.
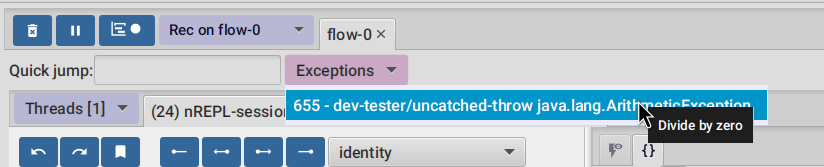
When an unwind situation is recorded a combobox will show up in the toolbar, containing the functions names together with the exceptions types. If you hover the mouse over any of them, a tooltip will display the exception message.
Clicking on any of them will position the stepper at that point in time so you can explore what happened before.
You can configure FlowStorm to automatically jump to exceptions with the Config menu by checking Auto jump to exception
which is disabled by default.
3.1.6. Locals
The locals panel will show the locals visible for the current point in time and their values at binding time.
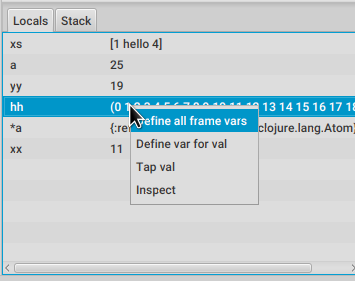
Right clicking on them will show a menu where you can :
-
define all
-
define the value with a name, so you can use it at the repl
-
inspect the value with a data window
-
tap the value as with
tap>
Define all will define all the bindings currently visible in the locals pane in the current form namespace.
This is useful for trying things at your editor as described here https://www.cognitect.com/blog/2017/6/5/repl-debugging-no-stacktrace-required
|
Note
|
Locals and mutable values
The Locals pane will show the value of each binding for a symbol at binding time, which are the same thing no matter where you are in the current block when working with immutable objects, but not when working with mutable ones. If what was bound was muttable in any way, you will be seeing the value at binding time, and not at current time. |
3.1.7. Stack
The stack panel will always show the current stacktrace. Be aware that the stacktrace only include functions calls that had been recorded, so if you aren’t recording everything there will be gaps.
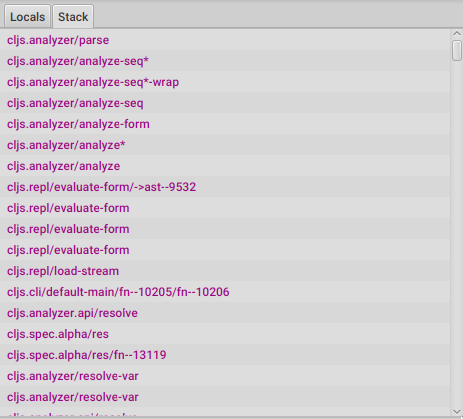
Double clicking on any of the stack entries will make the debugger jump to that point in time.
3.1.8. Value panels
Value panels show in many places in FlowStorm.
The value panel in the code tool always display a pretty print of the current expression value.
You can configure the print-level and print-meta for the pretty printing by using the controls at the top.
The value panel showing the current expression in the code stepper is a little bit special since it also contains a data window tab which allows you to quickly navigate the value or give it custom visualizations.
Define value for repl
Use the def button to define a var pointing to the current inspector value.
You can use / to provide a namespace, otherwise will be defined under [cljs.]user
3.1.9. Goto to file:line
Clicking on the Actions→Goto file:line menu allows you to search and jump to the first recording of a expression
with a file and line, given that one exists.
It will ask you for a file and line in the format of <file-path>:<line>.
It will search the file paths by str/ends-with? so if you have files like src/org/my_app/core.clj then
providing my_app/core.clj:42 should jump to that line, even if you didn’t provide the entire path.
This is useful because this functionality works by searching captured forms meta, and depending on your environment sometimes these paths contains the full path, sometimes just the classpath. What is important is that you use file names (with underscores) and not namespaces names.
3.2. Call Stack tree tool
The call stack tree tool is the second one of the Flows tab. It allows you to see the execution flow by expanding its call stack tree.

The call stack tree is useful for a high level overview of a complex execution and also as a tool for quickly moving through time.
You can jump to any point in time by double clicking on a node or by right clicking and on the context menu selecting Step code.
Use the button at the top left corner of the tree tool to show the current frame of the debugger in the tree.
There are also two value panels at the bottom that show the arguments and return value for the currently selected function call.
|
Note
|
Disabling the call stack tree tool
The call stack tree tool can be enable/disable on the fly if you are not using it and performance is an issue,
since keeping it updated can be expensive.
You can disable it from the Config menu or via the |
|
Note
|
ClojureScript async programming
Currently if you are using async/await in ClojureScript this tool could be inaccurate. This is because of the way the tree is being lazily built as you explore it and the structure the timelines end up on async environments. |
3.3. Functions tool
The functions tool is the third one of the Flows tab.
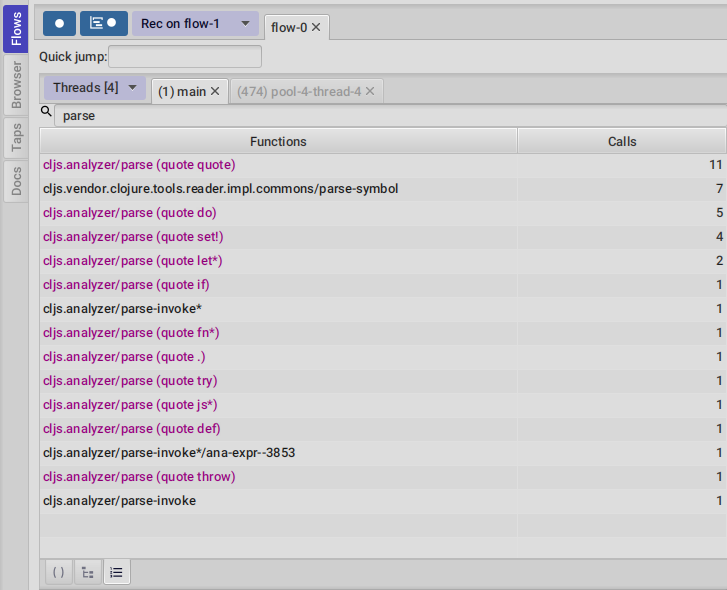
It shows a list of all traced functions sort by how many times the have been called.

Normal functions will be colored black, multimethods magenta and types/records protocols/interfaces implementations in green.
Together with the call stack tree it provides a high level overview of a thread execution, and allows you to jump through time much faster than single stepping.
You can search over the functions list by using the bar at the top.
3.3.1. Function calls
Clicking on the calls counter of any function will display all function calls on the right sorted by time. Each line will show the arguments vector for each call, and their return value. Use the check boxes at the top to hide some of the arguments.
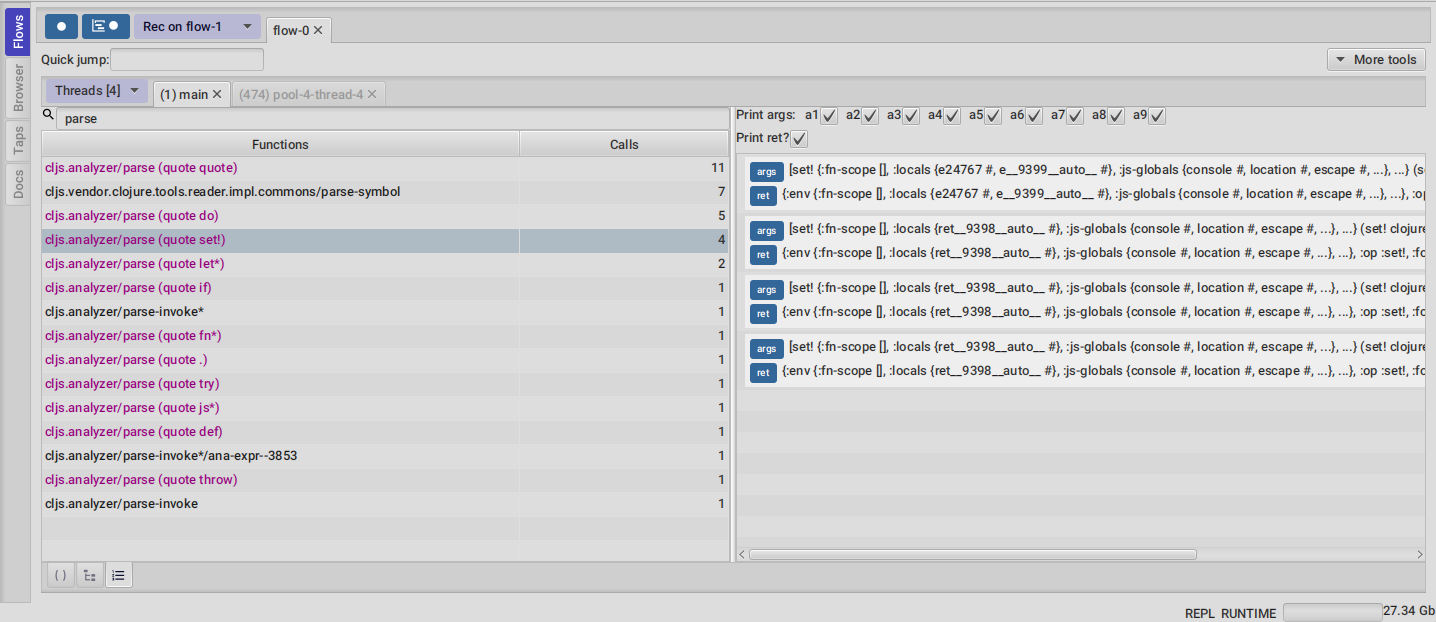
Double clicking on any row in the functions call list will jump to the stepper at that point in time.
You can also use the args and ret buttons to open the values on the inspector.
3.4. Multi-thread timeline
You can use this tool to record, display and navigate a total order of your recordings in a timeline. This can be used, for example, to visualize how multiple threads expressions interleave, which is sometimes useful to debug race conditions.
You enable/disable the multi-thread timeline recording using its button on the toolbar. Recording on the multi-thread timeline will make your program execution a little slower so it is recommended to have it paused unless you need it.
When you have something recorded on the multi-thread timeline you access the tool from the top right corner.
As an example, let’s say you record the execution this function :
(defn run-parallel []
(->> (range 4)
(pmap (fn [i] (factorial i)))
(reduce +)))By opening the tool a window like this should pop up :
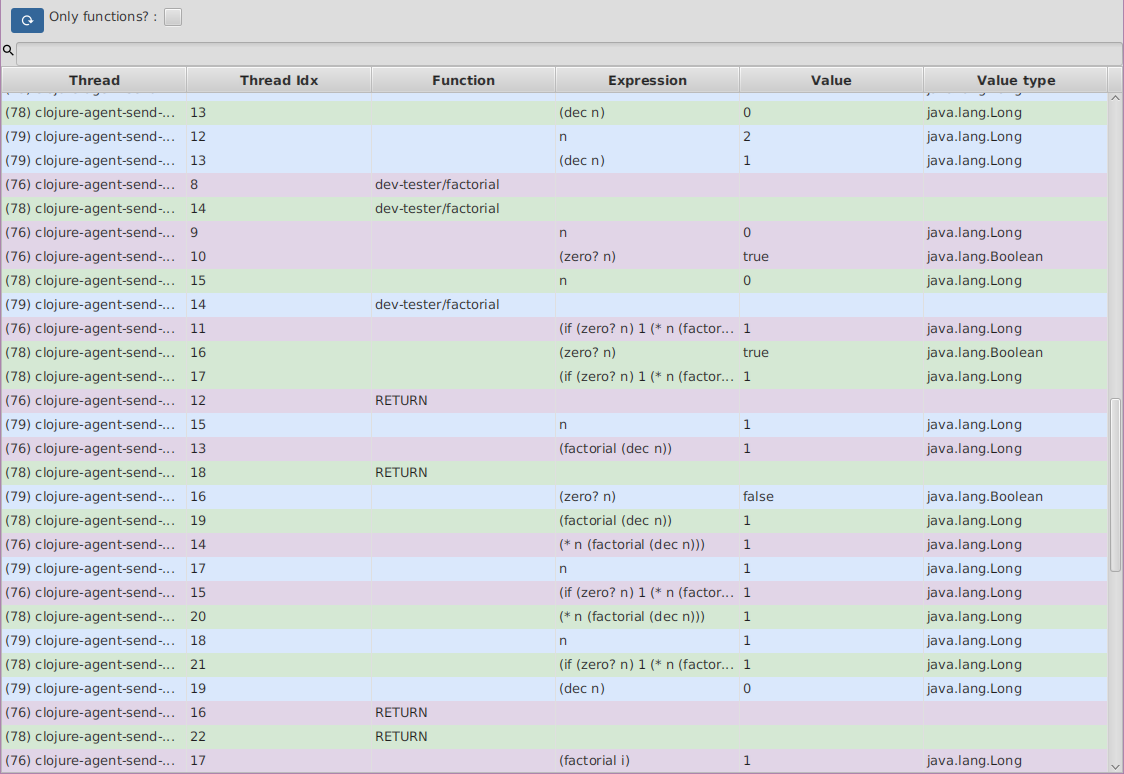
As you can see the timeline tool displays a linear representation of your expressions. Times flows from top to bottom and
each thread gets assigned a different color. Every time a function is called or returns you will see it under the Function
column, and for each expression executed you will see a row with its Expression and Value.
Double clicking any row will make your code stepper (on the main window) jump to the code at that point in time.
|
Note
|
Big recordings timeline
Rendering the timeline needs some processing to render each sub-form and print each value so be aware it could be slow if you try it on big recordings. |
There is also a Only functions? checkbox at the top that will retrieve only function calls and can be used to visualize
the threads interleaving at a higher level.
3.5. Printer
FlowStorm has a lot of functionality to replace printing to the console as a debugging method since most of the time it is pretty inefficient. Nonetheless, sometimes adding a bunch of print lines to specific places in your code is a very powerful way of understanding execution.
For this cases FlowStorm has the Printer tool, which allows you to define, manage and visualize print points, without the need
of re running your code. It will work on your recordings as everything else.
You can add and re run print points over your recordings as many times as you need. To add a print point, just right click on any recorded expression.
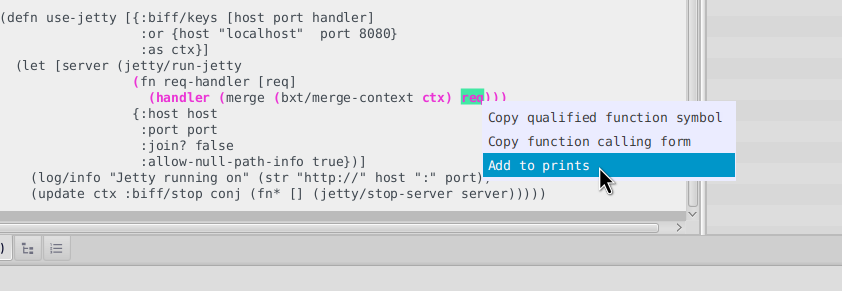
It will ask you for a couple optional fields.
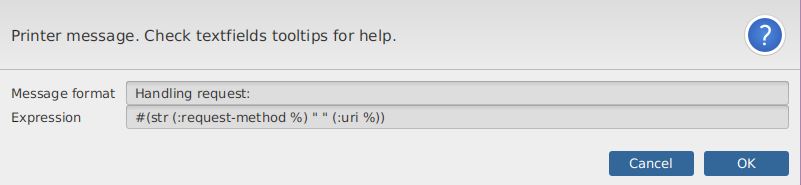
The Message format is the "println text". A message to identify the print on the printer output. Here you can use any text, in which you can
optionally use %s for the printed value, same as you would use it with format.
The Expression field can be use to apply a transformer function over the value before printing it. Useful when you want to see a part of the value.
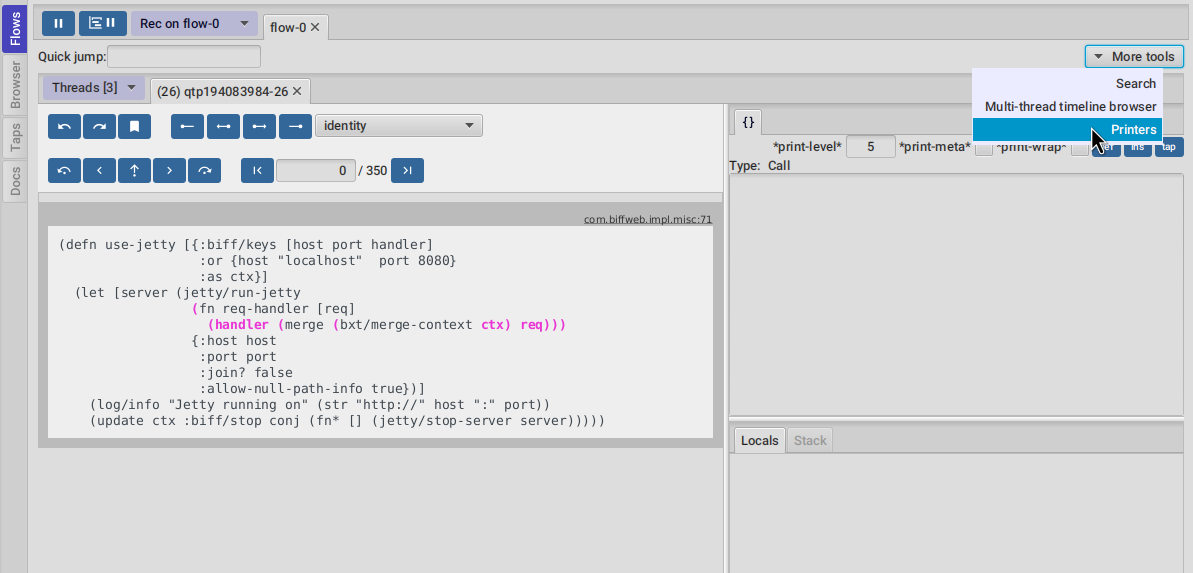
After you add them, you can access the Printers tool by navigating to More tools → Printers.
The threads selector allows you to select the thread the prints are going to run on.
Leaving it blank will run prints over all threads recordings (checkout the notes for caveats).
Clicking the refresh button will [re]run the printing again over the current recordings.
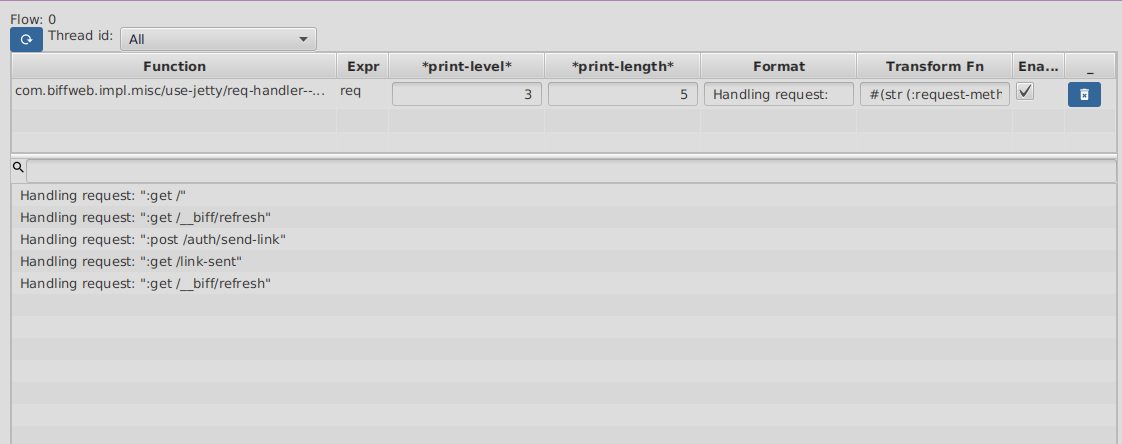
You can tweak your prints at any time, like changing the print-length, print-level, message, transform-fn or just temporarily disable any of them. When you are ok re-setting you prints, just click refresh and they will print again.
Double clicking on any printed line will jump to the Flows code tab, with the debugger pointed to the expression that generated the print.
|
Important
|
Multi-thread prints order
If you select |
3.6. Bookmarks
Bookmarks are another quick way of jumping around in code and they can be added from your code or the FlowStorm UI.
You can find you bookmarks on the top menu View → Bookmarks.
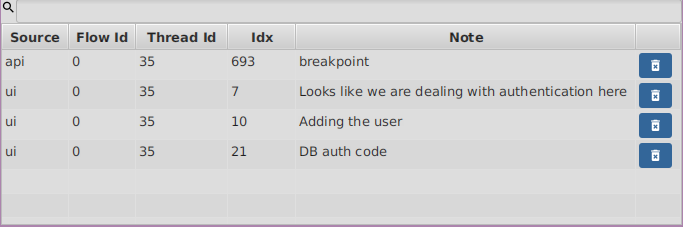
Double clicking on any bookmark will make the debugger jump back to its position.
3.6.1. Code bookmarks
You add code bookmarks by adding the (bookmark) statement to your code, which optionally accepts a label.
The first time a bookmark statement is executed it will make the FlowStorm UI jump to it. Since this behavior
is similar to a debugger statement in languages like Javascript, it is also aliased as (debugger) so you can
use whichever you prefer.
|
Note
|
ClojureScript support
This is currently only supported when using ClojureScriptStorm >= 1.11.132-9 |
3.6.2. UI bookmarks
UI bookmarks are useful when you find yourself jumping around, trying to understand a complex execution. They enable you to mark execution positions so you can come back to them later.

You can bookmark the current position by pressing the bookmark button in the code tool, next to your stepping controls. It will ask you the bookmark description.
4. Browser tool
The browser tool is pretty straight forward. It allows you to navigate your namespaces and vars, and provides ways of managing what gets instrumented.
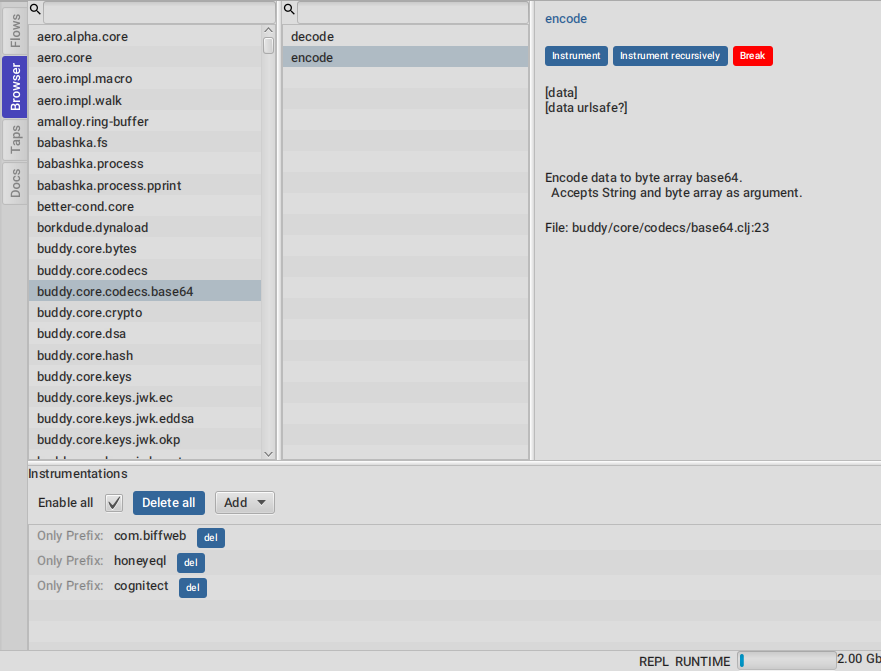
5. Outputs tool
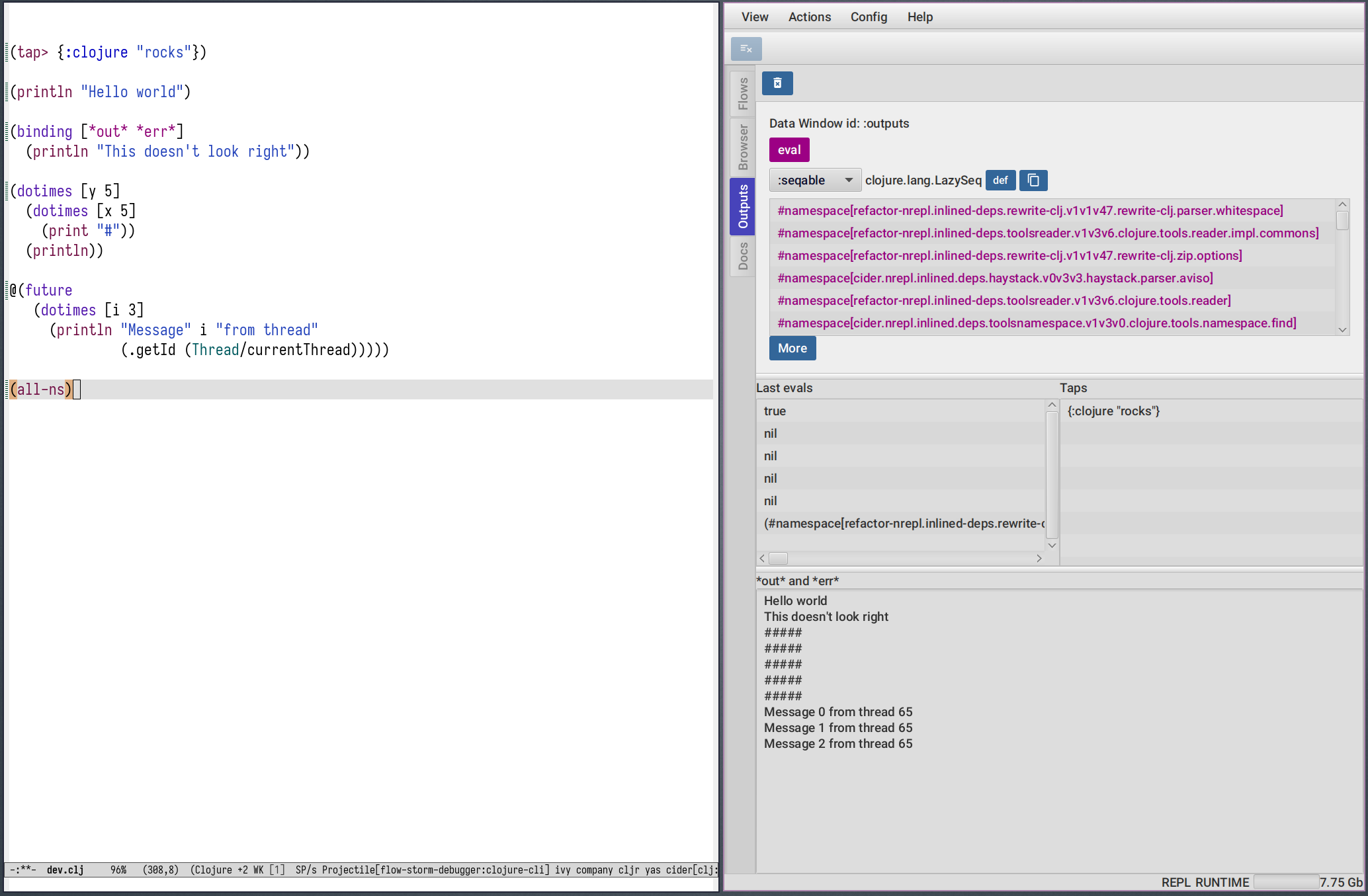
The outputs tool can be used instead of your normal IDE/Editor panel to visualize your evaluations
results, your taps outputs and your out and err streams writes (like printlns).
The advantages being :
-
Custom visualizations
-
Quick nested values navigation
-
Quick taps values navigation
-
Datafy nav navigation
-
Access to all previously tapped values
-
Access to the last 10 evaluated values (instead of just
*1and*2) -
Ability to search tapped values in Flows
The taps visualization system works out of the box while the evals result and printing capture currently depends on you using nrepl and starting with the flow-storm middleware. Checkout the outputs setup section for instructions.
|
Note
|
ClojureScript support
Only the taps viewer is currently supported on ClojureScript. The last evaluations and the out and err streams capture aren’t supported yet. |
5.1. Middleware setup
For using all the features in the Outputs tool you need to be using nrepl and start your repl with
flow-storm.nrepl.middleware/wrap-flow-storm middleware.
If you use Cider for example you can add it to cider-jack-in-nrepl-middlewares via customizing the global
value or by using .dir-locals.el.
5.2. Output data window
The top panel is a data window for displaying evaluations and taps. As soon as you evaluate or tap something it will be displayed here.
5.3. Last evals
The last evals pane gives you access to the last 10 evaluation results, same as *1 and *2.
Click on any value to display it on the top data window.
5.4. Taps
Everytime FlowStorm starts, it will add a tap, so whenever you tap> something
it will show on the taps list.
Click on any value to display it on the top data window.
If the tapped value has also been recorded as an expression in Flows, you can right click on it
and run Search value on Flows to move the debugger to that point in time.
|
Note
|
Search value on Flows
Be aware that if the code that taps your value is something like |
A #tap tag will also be available, which will tap and return so you can use it like (+ 1 2 #tap (* 3 4))
Use the clear button to clear the list.
There is also #tap-stack-trace. It will tap the current stack trace.
5.5. Out and Err streams
Everything written on out or err will be captured and displayed on the bottom panel.
You can copy anything from this area with normal tools.
6. Decompiler tool
|
Note
|
ClojureStorm version
To use the Decompiler tool you need to be running with ClojureStorm >= 1.13.* |
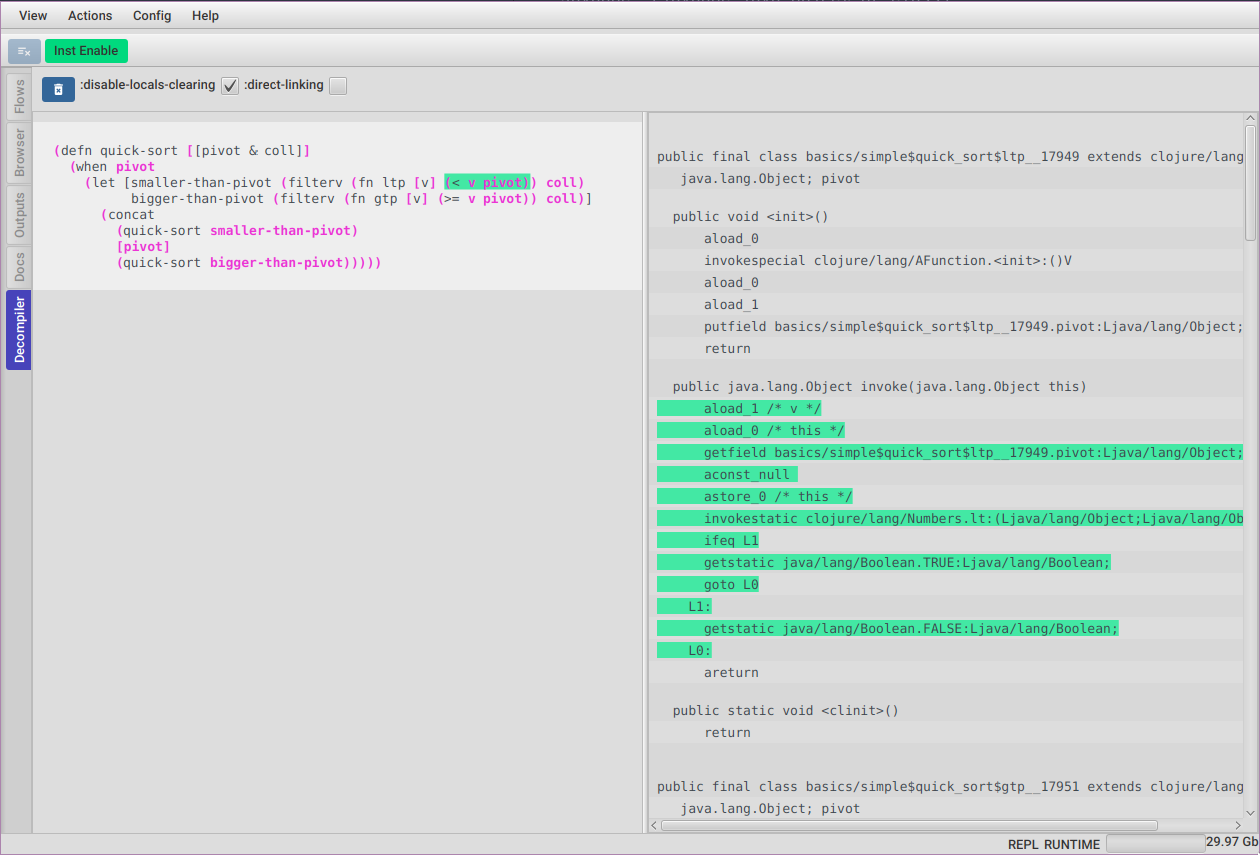
You can use the Decompiler tool to examine the bytecode generated by any form.
For using it you just need to eval any form on your repl marked with the ^:clojure.storm/collect-emitted meta, like :
^:clojure.storm/collect-emitted
(defn sum [a b c]
(+ a b c))When ClojureStorm sees a form marked like that it will collect all the bytecode it is emitting and then signal FlowStorm.
The form and its bytecode will be displayed under the Decompiler vertical tab.
You can click any expression on the form to highlight the bytecode emitted under that expression coordinate or the other way around, which is you can click any bytecode instruction and see which expression generated it.
You can add multiple forms or hit Ctrl+l to clear them.
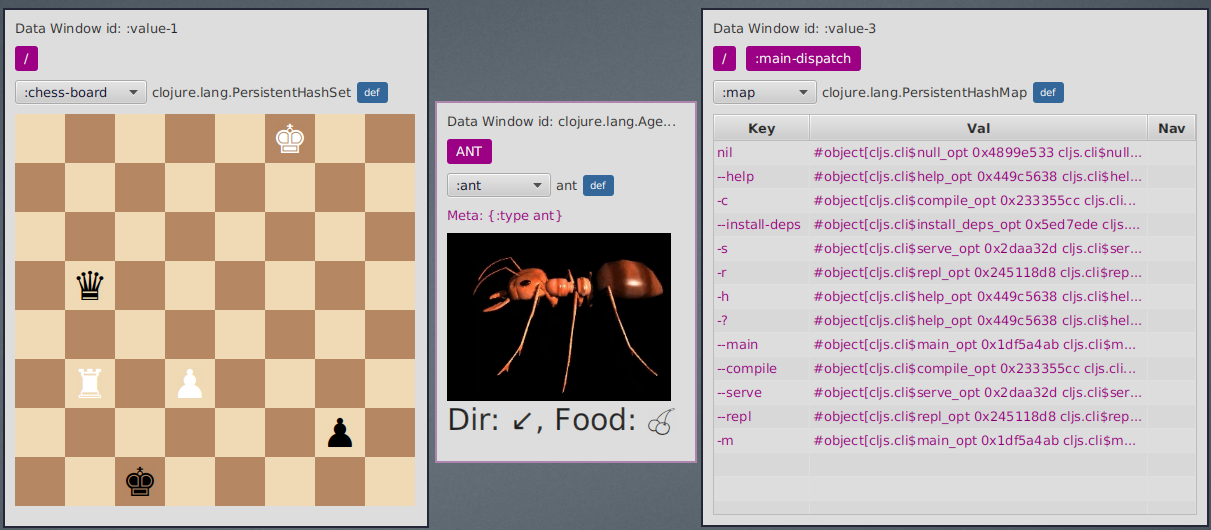
7. Data Windows
Data Windows are a user extensible tool to visualize and explore your data. Their role is to support :
-
a way to navigate nested structures in a lazy way
-
visualize and navigate metadata
-
multiple visualizations for each value
-
lazy/infinite sequences navigation
-
a way to define the current sub-values so you can use them at the repl
-
a mechanism for realtime data visualization
-
clojure.datafy navigation out of the box
-
tools for the user to add custom visualizations on the fly
The next sections will explore each of them.
7.1. Data navigation
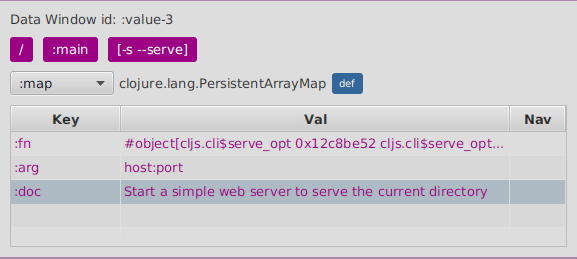
You can navigate into any key or value by clicking on it.
Use the breadcrumbs at the top to navigate back.
7.2. Metadata navigation
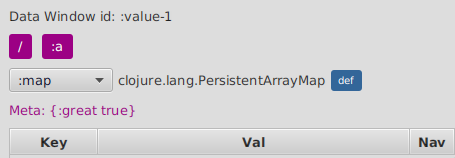
If any value contains metadata, it will be shown at the top. Clicking on it will make the data window navigate into it.
7.3. Multiple visualizers
You can change how to display your current value by using the visualizers selector dropdown at the top.
7.4. Sequences
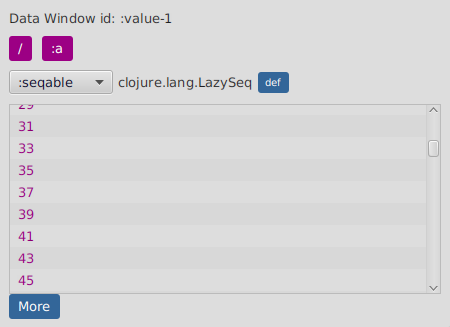
The seqable visualizer allows you to navigate all kind of sequences (even infinite ones) by bringing more pages on demand.
Click on More to bring the next page in.
7.5. Defining values
You can always define a var for the current value being shown on any data window by clicking the def button.
Clicking on it will raise a popup asking for a symbol name. If you don’t provide a fully qualified symbol
it will define the var under user or cljs.user if you are in ClojureScript.
A quick way to use it is to provide a short name, let’s say foo, and then access it from your
code like user/foo.
7.6. Realtime visualizations
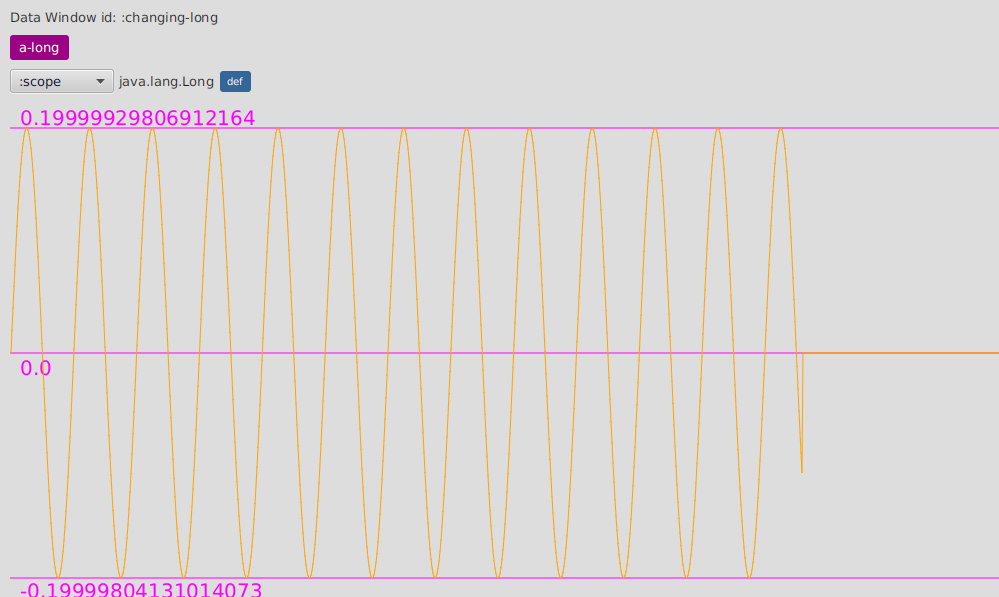
DataWindows not only support displaying and navigating values, but also updating them in real time from your application.
From your program’s code you can always create a data window with :
(flow-storm.api/data-window-push-val :changing-long-dw-id 0 "a-long")by providing a data window id, a value, and optionally the initial breadcrumb label.
But you can also update it (given that the selected visualizer supports updating like :scope for numbers) with :
(flow-storm.api/data-window-val-update :changing-long-dw-id 0.5)This data-window-val-update is pretty useful when called from loops or refs watches, specially paired
with a custom visualizer.
7.7. Clojure datafy/nav
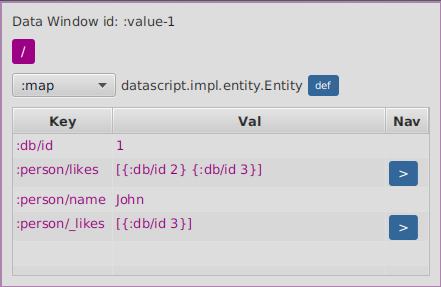
Data Windows support datafy nav out of the box. The data window will always be showing the result of
clojure.datafy/datafy of a value. For maps or vectors where keys provide navigation it will automatically
add a blue arrow next to the value.
Clicking on the value will just dig the data, while clicking on the blue arrow will navigate as with
clojure.datafy/nav applied to that collection on that key.
7.8. EQL pprint visualizer
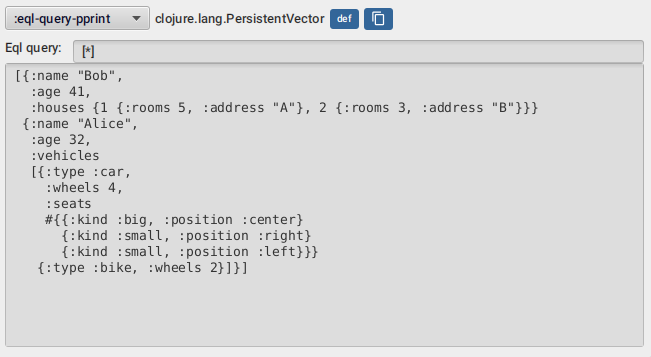
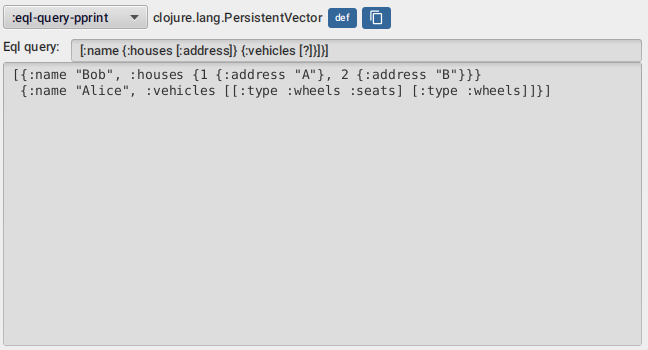
The eql-query-pprint visualizer allows you to explore your data "entities" by looking at subsets of it
using queries similar to datomic pull queries like in the screenshots above.
|
Note
|
Disable by default
The EQL query pprint is disable by default. To enable it call |
By entities it means maps which contains only keywords as their keys. Every other collection is just traversed.
This are all valid queries :
-
[*] -
[:name] -
[:name :age :vehicles] -
[:name :age {:vehicles [:type]}] -
[:name :age {:vehicles [?]}] -
[:name {:vehicles [*]}] -
[:name :age {:vehicles [:type {:seats [?]}]}] -
[:name :age {:vehicles [:type {:seats [:kind]}]}] -
[:name {:houses [:rooms]}]
The * symbol means include all keys, while the ? symbol means just list the keys, which helps
exploring big nested maps with many keys.
7.9. Custom visualizers
An important aspect of Data Windows is to be able to provide custom visualizers on the fly.
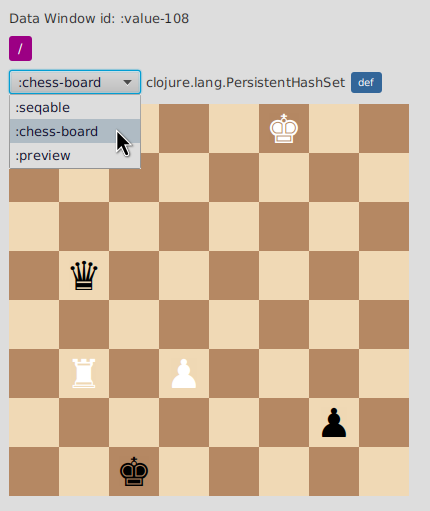
Let’s say we have model a chess board as a set of maps which represent our pieces.
(def chess-board
#{{:kind :king :player :white :pos [0 5]}
{:kind :rook :player :white :pos [5 1]}
{:kind :pawn :player :white :pos [5 3]}
{:kind :king :player :black :pos [7 2]}
{:kind :pawn :player :black :pos [6 6]}
{:kind :queen :player :black :pos [3 1]}})
(flow-storm.api/data-window-push-val :chess-board-dw chess-board "chess-board")If we open a data window with data-window-push-val we are going to see something like this :
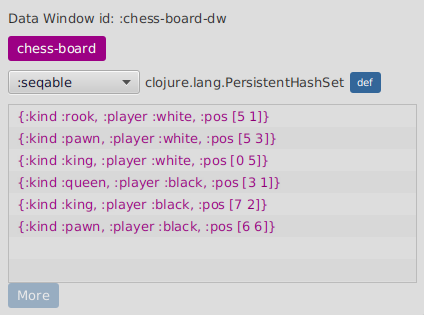
but we can do better, we can create a custom visualizer so we can see it like this :
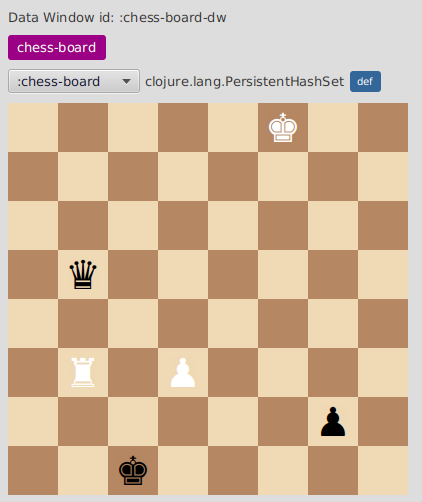
Data visualization in FlowStorm is composed of two things:
-
a data aspect extractor, which runs on the runtime process, and will build data for the visualization part
-
a visualizer, which runs on the debugger process, and will render extracted data for a value using javafx
For a basic Clojure session everything will be running under the same process, but this is not the case for ClojureScript or remote Clojure.
First let’s require some namespaces :
(require '[flow-storm.api :as fsa])
(require '[flow-storm.debugger.ui.data-windows.visualizers :as viz])
(require '[flow-storm.runtime.values :as fs-values])We can register a custom visualizer by calling register-visualizer.
(viz/register-visualizer
{:id :my-viz
:pred (fn [val] )
:on-create (fn [val] {:fx/node :any-java-fx-node-that-renders-the-value
:more-ctx-data :anything})
;; OPTIONALLY
:on-update (fn [val created-ctx-map {:keys [new-val]}] )
:on-destroy (fn [created-ctx-map] )
})The important part there are :id, :pred, and :on-create.
The :id will be the one displayed on the visualizers dropdown, and re-registering a visualizer
with the same id will replace the previous one.
:pred is a predicate on the data extracted from values, it should return true if this visualizer
can handle the value.
And :on-create will be a function that receives this value and renders a java fx node.
The val passed to on-create will also contain two special keywords :
-
:flow-storm.debugger.ui.data-windows.data-windows/dw-id The id of the data windows it’s being draw on
-
:flow-storm.debugger.ui.data-windows.data-windows/preferred-size (could be :small)
Optionally you can provide :on-update and :on-destroy.
:on-update will receive values from the runtime via fsa/data-window-val-update. It will also get a handle to
the original value (the one that created the DataWindow) and whatever map was returned by :on-create.
:on-destroy will be called everytime a visualizer gets removed, because you swapped your current visualizer
or because you went back with breadcrums. It can be useful in case you need to clear resources created by
:on-create.
:pred and :on-create will not receive the original value but the extracted aspects of it after
all registered extractors run.
You can check the data available to your visualizer for a value in a data window by calling :
(viz/data-window-current-val :chess-board-dw)If the data already extracted from your value is not enough for your visualizer you can register another extractor.
7.9.1. Data aspect extraction
(fs-values/register-data-aspect-extractor
{:id :chess-board
:pred (fn [val _]
(and (set? val)
(let [{:keys [kind player pos]} (first val)]
(and kind player pos))))
:extractor (fn [board _] {:chess/board board})})In this case we are going to register and extractor that will only run for vals which are sets and
contains at least one element which is a map with :kind, :player and :pos.
The extracted data will be the entire board.
All ids of extractors that applied for a value will be appended under ::fs-values/kinds of the value
as you will see next.
7.9.2. Visualizers
Now we can register a visualizer that will show only on values which contains a :chess-board kind.
(import '[javafx.scene.layout GridPane])
(import '[javafx.scene.control Label])
(viz/register-visualizer
{:id :chess-board
;; only be available if the chess-board data extractor run on this value
:pred (fn [val] (contains? (::fs-values/kinds val) :chess-board))
;; use the chess/board info to render a board with java fx
:on-create (fn [{:keys [chess/board]}]
(let [kind->sprite {:king "♚" :queen "♛" :rook "♜" :bishop "♝" :knight "♞" :pawn "♟"}
pos->piece (->> board
(mapv #(vector (:pos %) %))
(into {}))]
{:fx/node (let [gp (GridPane.)]
(doall
(for [row (range 8) col (range 8)]
(let [cell-color (if (zero? (mod (+ col (mod row 2)) 2)) "#f0d9b5" "#b58863")
{:keys [kind player]} (pos->piece [row col])
cell-str (kind->sprite kind "")
player-color (when player (name player))]
(.add gp (doto (Label. cell-str)
(.setStyle (format "-fx-background-color:%s; -fx-font-size:40; -fx-text-fill:%s; -fx-alignment: center;"
cell-color player-color))
(.setPrefWidth 50))
(int col)
(int row)))))
gp)}))})7.9.3. ClojureScript
Using custom visualizers with ClojureScript (or other remote environments) is a little bit more involved.
Registering aspect extractors is exaclty the same, since they run on the runtime (browswer, node, etc), but
custom visualizers should be registered on the debugger process. For this you need to create your visualizers in some
namespace, let’s say on /dev/visualizers.clj, add the dev folder to your classpath and then running the debugger UI
with something like :
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debugger :port 9000 :repl-type :shadow :build-id :my-app :pre-require visualizersNotice the last option :pre-require visualizers. This will allow you to load the just defined visualizers namespace before
starting the UI.
7.10. Default visualizers
You can make any visualizer the default by calling add-default-visualizer which takes a predicate on the val-data (the same received by :on-create) and
a visualizer key, like this :
(viz/add-default-visualizer (fn [val-data] (contains? (:flow-storm.runtime.values/kinds val-data) :chess-board)) :chess-board)For all FlowStorm provided visualizers take a look at flow-storm.debugger.ui.data-windows.visualizers namespace.
Default visualizers predicates are added in a stack, and tried from the top. This means that you can always overwrite a default by adding a new one.
8. Thread breakpoints
FlowStorm is a tracing debugger, which means it can record what is happening without the need of stopping your programs execution. This is all fine but doesn’t cover every possible situation. There are cases where recording everything is impractical, and even if you can start/stop recording whenever you want, being able to automatically stop your threads at certain points is useful.
For these cases, FlowStorm has the ability to set thread breakpoints, which means to define points (functions) in the execution of your program where you want your threads to wait. While the threads are waiting you can explore what happened so far.
As soon as a thread hits a break function, if recording is on, it will be blocked, and a "Threads blocked" menu will show up in the UI. You can use this menu to unblock different threads.
Once you are done, you can pause recording using the pause button in the main toolbar and un-block every thread.
You can define thread breakpoints in two ways :
-
Using the browser (like in the image below), you can navigate to any function and click on the
Breakbutton. This will block the calling thread every time the selected function gets called. -
Or you can also install a break by calling (flow-storm.api/break-at 'my-proj.core/some-fn)
|
Note
|
Conditional threads breakpoints
The break-at fn accepts a second argument where you can provide a predicate that will be called with the same arguments
of the function you are breaking. It will only break when the predicate returns true. If you don’t
provide a predicate it will default to |
You can remove breakpoints by :
-
Clicking on the browser instrumentation list delete buttons
-
Calling
flow-storm.api/remove-breakto remove a single breakpoint -
Calling
flow-storm.api/clear-breaksto remove all breakpoints
9. Programmable debugging
FlowStorm gives you full access to its internal indexes from the repl in Clojure and ClojureScript. These allows you to explore your recordings using Clojure and write small programs to analyze them if what’s provided by the GUI is not enough.
Most of what is documented here is also documented in the flow-storm.runtime.indexes.api namespace docstring, which
you can retrieve by evaluating (doc flow-storm.runtime.indexes.api). In fact, this is the only namespace you need to
require on your repl in order to work with your recordings.
Let’s say you have recorded some execution and now you want to work with the recordings from the repl.
So first we require the api ns as ia.
(require '[flow-storm.runtime.indexes.api :as ia])Now from the UI, you can get the thread-id of your recordings (the number next to the thread name) which you will need for accessing them from the repl.
9.1. Timelines
Let’s say you want to explore recordings on thread 32. You can retrieve its timeline by calling ia/get-timeline like this :
(def timeline (ia/get-timeline 32))Once you have the timeline you can start exploring it.
The timeline implements many of the Clojure basic interfaces, so you can :
user> (count timeline)
798
user> (take 3 timeline)
; (#flow-storm/fn-call-trace [Idx: 0 org.my-app/run-server]
; #flow-storm/fn-call-trace [Idx: 1 org.my-app/read-config]
; #flow-storm/fn-call-trace [Idx: 2 org.my-app/check-config])
user> (get timeline 0)
; #flow-storm/fn-call-trace [Idx: 0 org.my-app/run-server]The easiest way to take a look at a thread timeline is with some code like this :
(->> timeline
(take 3)
(map ia/as-immutable))
; ({:type :fn-call,
; :fn-ns "org.my-app",
; :fn-name "run-server",
; :ret-idx 797,
; :fn-call-idx 0,
; :parent-idx nil,
; :fn-args [],
; :form-id -798068730,
; :idx 0}
; ...
; ...)In most cases converting all entries into maps with ia/as-immutable is enough, but if you want a little bit more
performance you can access entries information without creating a immutable map first.
Timelines entries are of 4 different kinds: FnCallTrace, FnReturnTrace, FnUnwindTrace and ExprTrace.
You can access their data by using the following functions depending on the entry :
All kinds :
-
as-immutable -
fn-call-idx
ExprTrace, FnReturnTrace and FnUnwindTrace :
-
get-coord-vec
ExprTrace, FnReturnTrace :
-
get-expr-val
FnUnwindTrace :
-
get-throwable
FnCallTrace :
-
get-fn-name -
get-fn-ns -
get-fn-args -
get-fn-parent-idx -
get-fn-ret-idx -
get-fn-bindings
You can also access the timeline as a tree by calling :
-
callstack-root-node -
callstack-node-childs -
callstack-node-frame-data
Take a look at their docstrings for more info.
9.2. Forms
You can retrieve forms by form id with get-form and then use get-sub-form-at-coord and a coordinate.
Here is a little example :
;; retrieve some expression entry into expr
user> (def expr (-> timeline
(get 3)
ia/as-immutable))
user> expr
{:type :expr, :coord [2 2 1], :result 4, :fn-call-idx 2, :idx 3}
;; retrieve the fn-call entry for our expr
user> (def fn-call (-> timeline
(get (:fn-call-idx expr))
ia/as-immutable))
user> fn-call
{:type :fn-call,
:fn-ns "dev-tester"
:fn-name "other-function",
:form-id 1451539897,
...}
;; grab it's form
user> (def form (-> fn-call
:form-id
ia/get-form
:form/form))
user> form
(def other-function (fn [a b] (+ a b 10)))
;; lets look at the sub-form from form at our expr coordinate
user> (ia/get-sub-form-at-coord form (:coord expr))
a9.3. Multi-thread timeline
If you have recorded a multi-thread timeline, you can retrieve it with total-order-timeline like this :
(def mt-timeline (ia/total-order-timeline))which you can then iterate using normal Clojure functions (map, filter, reduce, get, etc).
The easiest way to explore it is again with some code like this :
user> (->> mt-timeline
(take 3)
(map ia/as-immutable))
({:thread-id 32,
:type :fn-call,
:fn-call-idx 0,
:fn-ns "org.my-app",
:fn-name "run",
:fn-args [],
:ret-idx 797,
:parent-idx nil,
:form-id -798068730,
:idx 0}
...
...)Notice that each of these entries contains a flow-id and thread-id also.
9.4. Other utilities
There are other utitities in the api ns that could be useful, some of the most interesting ones :
-
find-expr-entryuseful for searching expressions and return values with different criteria. -
find-fn-call-entryuseful for searching functions calls with different criteria. -
stack-for-frame -
fn-call-stats
Take a look at their docstrings for more info.
10. LLM agents
You can teach a LLM how to use FlowStorm’s api to help you analyze your recordings.
If you are using the amazing clojure-mcp you just need to upload one more file that teaches the LLM FlowStorm’s basics from the repl.
Here is a very basic chat asking Claude to look at some recordings of a buggy TODO’s web application.
11. Remote debugging
You can remotely debug any Clojure application that exposes a nrepl server.
In terms of dependencies, the debuggee side should be setup the same as a normal local setup, with the optional change that you can use
flow-storm-inst instead of flow-storm-dbg, being the former a slimmed down version of the later one that
doesn’t contain some libraries used only by the UI, but using the full flow-storm-dbg is also ok.
11.1. SSH tunnel
The easiest way to debug a remote application is via a ssh tunnel. You can create it from your dev box like this :
ssh -L 9000:localhost:9000 -R 7722:localhost:7722 my-debuggee-box.comassuming your remote process at my-debuggee-box.com has started a nrepl server listening on port 9000 and that the debugger websocket server is running on the default port.
After the tunnel is established, you can run you debugger UI like this :
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debugger :port 9000and that is it.
If you need to connect the debugger to a remote process without a ssh tunnel or you need to configure the websocket server port you can do it like this :
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debugger :port NREPL-PORT :runtime-host '"YOUR-APP-BOX-IP-ADDRESS"' :debugger-host '"YOUR-BOX-IP-ADDRESS"' :ws-port WS-SERVER-PORT11.2. Out of process
Sometimes you are not debugging across a network but you want to run the FlowStorm UI on a different process.
A couple of aliases that can help for this :
{:aliases
;; for your system process
{:runtime-storm {:classpath-overrides {org.clojure/clojure nil}
:extra-deps {com.github.flow-storm/clojure {:mvn/version "1.13.0-alpha4"}
com.github.flow-storm/flow-storm-inst {:mvn/version "4.7.0"}}}
;; for the FlowStorm GUI process
:ui-storm {:extra-deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}
:exec-fn flow-storm.debugger.main/start-debugger
:exec-args {:port 7888}}}} ;; set your nrepl port here!With those aliases you can start your application process by adding :runtime-storm and that is it.
To start the FlowStorm UI, go to another terminal and run clj -X:ui-storm.
11.3. Docker
If you run you process inside a docker container, here is a basic template for using FlowStorm with it https://github.com/jpmonettas/docker-flow-storm-basic
12. Dealing with too many traces
When recording an application’s execution (specially when using ClojureStorm or ClojureScriptStorm) it could happen that your process starts running out of heap. This section documents some tools FlowStorm provides to deal with this situations.
Most of the time, having the recording paused and just enabling it right before executing the action you are interested in is enough, but when it isn’t, here are some other options.
12.1. Fn call limits
A common situation is to see some high frequency functions adding a lot of noise to your recordings. For example a MouseMove event processing will generate a lot of recordings while you use your app. There are a couple of ways to limit your functions calls by thread. You can identify this kind of functions with the functions tool.
One tool you can use in this situations is the flowstorm.threadFnCallLimits JVM prop.
For example, you can add "-Dflowstorm.threadFnCallLimits=org.my-app/fn1:2,org.my-app/fn2:4" so every time the system starts, limits will be set for
org.my-app/fn1 and org.my-app/fn2. The number next to them is the limit. When a function reaches the limit FlowStorm will stop recording calls
to it and all the functions down its callstack.
You can also modify the limits from your repl, by calling flow-storm.runtime.indexes.api/[add-fn-call-limit|rm-fn-call-limit|get-fn-call-limits].
In ClojureScript you need to call them via your cljs repl api.
These limits are per thread, so when a thread recording is created it will start with the current defined counters, and each time a function gets called the counter will decrement. When it reaches zero the function and all functions calls under it will stop being recorded.
When you clear your threads you are also clearing its limit counters, so next time you record something new counters will be initialized from your global limits definitions.
12.2. Trace and heap limits
If you are tracing some code that ends up in a infinite loop the debugger will choke on too many traces, making everything slow and your only option is probably to restart it.
For preventing this, FlowStorm provides a couple of fuse/breakers, on threads trace count and on heap limits.
They are off by default but you can enable it from the Config menu.
12.2.1. Trace limits
Let’s say you added a thread trace limit of 1000. If you now run any code where a thread generates more than a 1000 traces FlowStorm will only record those first 1000 traces and then discard the rest as if recording is off for that thread, while it will keep recording threads that haven’t reached the limit.
Your code will continue execution as normal, which you can break using your normal editor breaking commands if its an infinite loop, but now you have recordings to look at what is going on.
You can set a limit of 0 to disable it again.
You can set this limits at startup via the JVM options "-Dflowstorm.threadTraceLimit=1000" and
"-Dflowstorm.throwOnLimit=true".
12.2.2. Heap limits
Another option is to automatically stop recording when a certain heap limit in megabytes is reached.
This can also be set at startup via the JVM option "-Dflowstorm.heapLimit=1000", which means stop recording
as soon as we used 1000Mb of heap space.
13. Dealing with mutable values
FlowStorm will retain all values pointers when code executes so you can analyze them later. This works great with immutable values but when your code uses mutable values like this :
(let [a (java.util.ArrayList.)]
(count a)
(.add a "hello")
(count a)
(.add a "world")
(.add a "!"))then every time you step over a it will contain the last value ["hello" "world" "!"].
You can fix this situation by extending the flow-storm.runtime.values/SnapshotP protocol like this :
(extend-protocol flow-storm.runtime.values/SnapshotP
java.util.ArrayList
(snapshot-value [a] (into [] a)))to provide FlowStorm a way of creating a snapshot of the mutable value.
|
Note
|
ClojureStorm
If you are using ClojureStorm evaluate the previous defmethod in a ns that is not being instrumented to avoid an infinite recursion. |
Be aware that this is tricky in multithreading situations, as always with mutable values.
|
Note
|
Automatic derefing
FlowStorm will automatically deref Atoms, Refs, Agents, Vars and all pending-realized derefables on tracing
so no need to implement |
|
Note
|
Snapshoting and nested values
Snapshoting only applies to direct references to mutable values. For example if you have an atom inside a nested immutable collection, it will not be snapshoted every time that collection expression is being recorded, because the value being recorded is not a reference to an atom. If this is important to you, you can still define snapshot-value for clojure.lang.PersistentArrayMap, etc, and walk it down snapshoting everything mutable inside. |
|
Note
|
snapshot-value and memory footprint
Although snapshot-value was created as a way to deal with mutable values it can be used to replace any value by another in the recordings, which can be useful in other situations like reducing memory footprint when you don’t need the entire value to be recorded. |
14. Controlling instrumentation
If you are using ClojureStorm or ClojureScriptStorm it is important to learn how to control what gets instrumented and how to uninstrument things. You can configure what gets instrumented automatically on startup via JVM properties but also change this while your repl is running without the need to restart it.
FlowStorm by default will automatically figure out what to instrument from your project, which
you can always disable by setting the -Dclojure.storm.instrumentAutoPrefixes=false.
|
Note
|
How are auto prefixes calculated?
When the process starts it will scan all source folders on the classpath (everything not inside a jar containing clojure files) and build
a set of all top level namespace. All namespaces under those will be instrumented.
Currently it doesn’t detect single level namespaces, like when you have |
If you prefer to be explicit about what gets instrumented you can use the JVM property "-Dclojure.storm.instrumentOnlyPrefixes=YOUR_INSTRUMENTATION_STRING"
where YOUR_INSTRUMENTATION_STRING should be a comma separated list of namespaces prefixes like :
my-project.,lib1.,lib2.core
which means automatically instrument my-project.* (which includes all sub namespaces), all lib1.* and only everything under lib2.core
All this can be changed after without restarting your repl from FlowStorm browser.
14.1. Turning instrumentation on an off
You can turn instrumentation on an off by using the button on the toolbar. Remember that the change of this setting will only be effective on newly compiled code.
14.2. Setup startup instrumentation
The first important thing is to setup your instrumentation correctly via JVM properties :
On ClojureStorm :
-Dclojure.storm.instrumentOnlyPrefixes=my-app,my-lib
-Dclojure.storm.instrumentSkipPrefixes=my-app.too-heavy,my-lib.uninteresting
-Dclojure.storm.instrumentSkipRegex=.*test.*On ClojureScriptStorm :
-Dcljs.storm.instrumentOnlyPrefixes=my-app,my-lib
-Dcljs.storm.instrumentSkipPrefixes=my-app.too-heavy,my-lib.uninterestingApart from instrumentOnlyPrefixes which you probably already know, there is instrumentSkipPrefixes which also
accepts a comma separated list of namespaces prefixes to skip, and instrumentSkipRegex with accepts a regex for
namespaces to skip. All these together allows you to instrument you whole app but some undesired namespaces.
The next important thing is to be able to enable/disable instrumentation and add/remove prefixes without restarting the repl.
14.3. Modifying instrumentation with the Browser
You can use the Browser tool to check and change on the fly the prefixes you configured in the previous section.
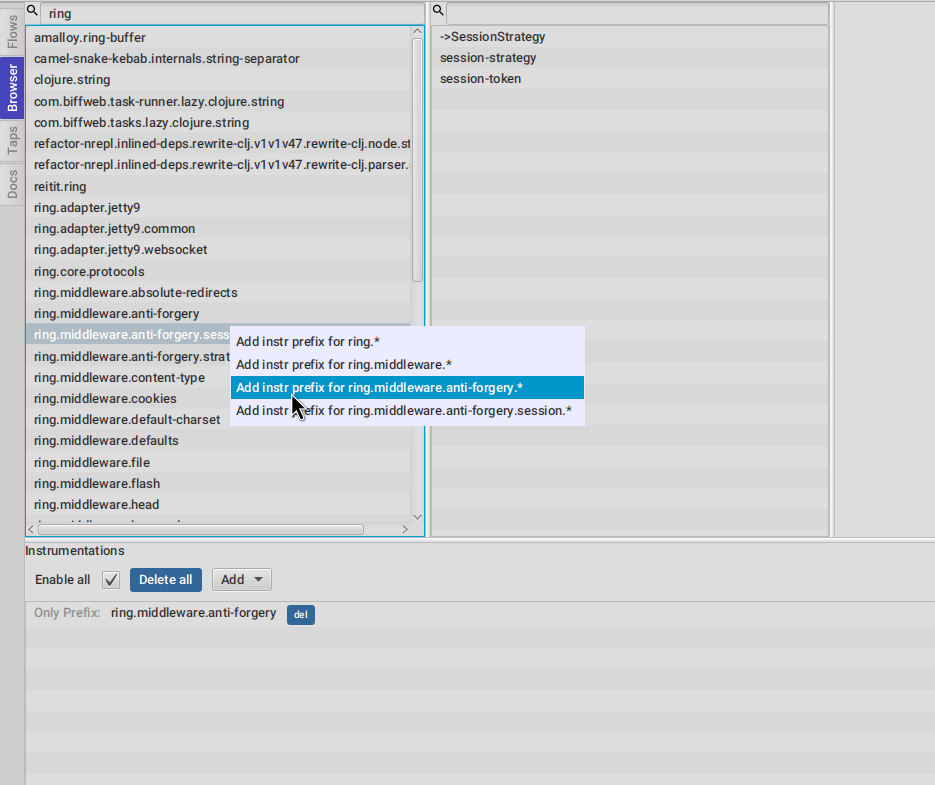
Right clicking any namespace will give you options for what level of a namespace you want to instrument.
On the bottom pane (instrumentations) you will see your current instrumentation configuration (if any). Here we can see that everything under
ring.middleware.anti-forgery will be instrumented every time something inside it gets compiled.
You can remove entries using the del buttons or temporarily disable/enable them using the Enable all checkbox.
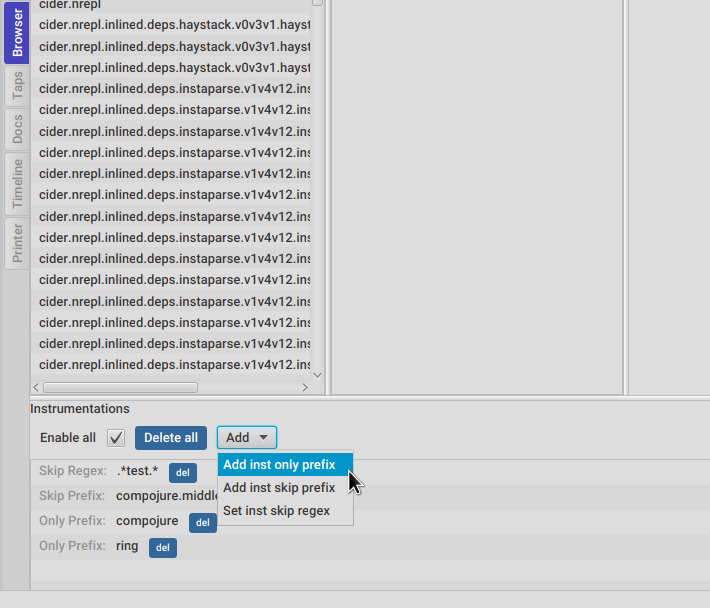
You can use the Add menu in the picure above to add instrumentation prefixes.
After changing any prefix FlowStorm will ask if you want it to reload the affected namespaces for you. Namespace reloading will all reload all namespaces it depends on in topological order, so it shouldn’t break your system in any way.

You can also provide functions to be called before and after reloading in case you need to stop and start your system with :
(flow-storm.api/set-before-reload-callback! (fn [] (println "Before reloading")))
(flow-storm.api/set-after-reload-callback! (fn [] (println "After reloading")))|
Note
|
Instrumentation
Just changing the prefixes without reloading will not make your currently loaded code [un]instrumented.
If you haven’t let FlowStorm reload them for you, you can always recompile them as usual with your editor commands or
by executing something like |
14.4. Instrumentation in Vanilla FlowStorm
|
Note
|
ClojureStorm
Instructions here only apply to vanilla FlowStorm. If you are using ClojureStorm or ClojureScriptStorm (recommended) this is done automatically for you, so just skip this section. |
Code instrumentation in FlowStorm is done by rewriting your code, in a way that doesn’t change its behavior but when executed will trace everything the code is doing.
14.4.1. Instrument any form with #trace
You can instrument any top level form at the repl by writing #trace before it, like this :
#trace
(defn sum [a b]
(+ a b))and then evaluating the form.
- important
-
#traceis meant to be used with forms that don’t run immediately, like: defn, defmethod, extend-type, etc. Use#rtraceto trace and run a form, like#rtrace (map inc (range 10)).
14.4.2. Run code with #rtrace
#rtrace is useful in two situations :
First, when instrumenting and running a simple form at the repl, like:
#rtrace (-> (range) (filter odd?) (take 10) (reduce +))14.4.3. Instrument namespaces
FlowStorm allows you to instrument entire namespaces by providing flow-storm.api/instrument-namespaces-clj.
You call it like this :
(instrument-namespaces-clj #{"org.my-app.core" "cljs."})The first argument is a set of namespaces prefixes to instrument. In the previous example it means
instrument all namespaces starting with org.my-app.core, and all starting with cljs.
The second argument can be a map supporting the following options :
-
:excluding-nsa set of strings with namespaces that should be excluded -
:disablea set containing any of #{:expr:binding:anonymous-fn} useful for disabling unnecessary traces in code that generate too many -
:verbose?when true show more logging
14.4.4. What can’t be instrumented?
These are some limitations when instrumenting forms :
-
Very big forms can’t be fully instrumented. The JVM spec has a limit on the size of methods and instrumentation adds a lot of code. When instrumenting entire namespaces, if you hit this limit on a form a warning will printed on the console saying
Instrumented expression is too large for the Clojure compilerand FlowStorm automatically tries to instrument it with a lighter profile, by disabling some instrumentation. -
Functions that call recur without a loop
-
Functions that return recursive lazy sequences. Like
(fn foo [] (lazy-seq (… (foo))))
14.4.5. Un-instrument code
Un-instrumenting code that has been instrumented with #trace or #ctrace is straight forward, just remove the tag and re evaluate the form.
To un-instrument entire namespaces you can use flow-storm.api/uninstrument-namespaces-clj which accept a set of namespaces prefixes.
14.4.6. Instrument with the browser
Most of the time you can instrument code by just clicking in the browser. The only exceptions are functions that were just defined in the repl and weren’t loaded from a file.
Instrument vars
Using the browser you can navigate to the var you are interested in and then use the instrument button to instrument it.
There are two ways of instrumenting a var :
-
Instrument (instrument just the var source code)
-
Instrument recursively (recursively instrument the var and all vars referred by it)
Instrument namespaces
Using the browser you can also instrument multiple namespaces. Do this by selecting the namespaces you are interested in and then a right click should show you a menu with two instrumentation commands.
-
Instrument namespace :light- record function arguments and return values (not expressions, no bindings tracing) -
Instrument namespace :fullfully instrument everything
Light instrumentation is useful when you know the functions generate too many traces, so you can opt to trace just functions calls and returns. You can then fully instrument whatever functions you are interested in.
Un-instrument code
The bottom panel shows all instrumented vars and namespaces.
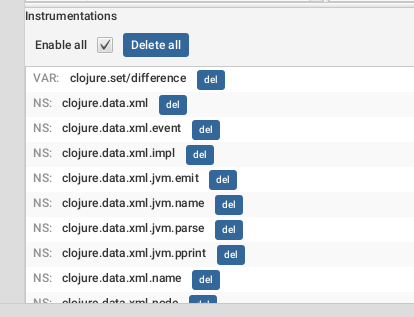
You can un-instrument them temporarily with the enable/disable checkbox or permanently with the del button.
Fully instrument a form from the code view
If you have instrumented a form with the :light profile you can fully instrument it by right clicking on the current form
and then clicking Fully instrument this form.
15. Plugins
FlowStorm plugins allows you to add specialized tools to visualize and interact with your recordings.
15.1. Using plugins
For using a pluggin follow each plugging instructions which should normally consists of adding
its dependency and then setting the jvm prop flowstorm.plugins.namespaces with all the main
namespaces of the plugins you want loaded at startup, like : "-Dflowstorm.plugins.namespaces=flow-storm.plugins.my-plugin.all"
After that you should see a new vertical tab with the plugin UI as you can see here :
15.2. Creating plugins
Creating a pluging consists of two parts :
-
The runtime code that will analyze the recordings and expose an api for the UI
-
The UI component which will visualize and interact with the data via the runtime api
This split is not required, but it is important if you want your plugin to support ClojureScript also or remote Clojure debugging where the UI is not running in the same process as the runtime.
This components are normally split in two files, a runtime.clj and ui.clj, but you can name them however you want.
We are going to go over each part in more detail but for a real plugin please checkout the core.async.flow plugin.
15.2.1. Runtime
Here is a runtime file template you can use :
(ns flow-storm.plugins.my-plugin.runtime
(:require [flow-storm.runtime.indexes.api :as ia]
[flow-storm.runtime.debuggers-api :as dbg-api]))
(defn my-data-extraction [flow-id thread-id]
(let [timeline (ia/get-timeline flow-id thread-id)]
(reduce (fn [acc tl-entry]
;; extract some interesting info from the timeline
)
{}
timeline)
))
;; Expose your function so it can be called from the UI part
(dbg-api/register-api-function :plugins.my-plugin/extract-data my-data-extraction)15.2.2. UI
Here is a ui file template you can use :
(ns flow-storm.plugins.my-plugin.ui
(:require [flow-storm.debugger.ui.plugins :as fs-plugins]
[flow-storm.debugger.runtime-api :as runtime-api :refer [rt-api]])
(:import [javafx.scene.control Label]))
(fs-plugins/register-plugin
:my-plugin
{:label "My plugin"
:css-resource "flow-storm-my-plugin/dark.css"
:dark-css-resource "flow-storm-my-plugin/dark.css"
:light-css-resource "flow-storm-my-plugin/light.css"
:on-focus (fn [{:keys [some-other-data]}]
;; This gets called everytime the plugin tab gets focused
)
:on-create (fn [_]
{:fx/node (Label.
;; You can call your runtime registered function
(str (runtime-api/call-by-fn-key rt-api :plugins.my-plugin/extract-data [0 10])))
:some-other-data 42})
:on-flow-clear (fn [flow-id {:keys [some-other-data]}]
;; this gets called everytime a flow is discarded so you can update your plugin UI accordignly
)
})Styling plugins UIs
As you saw in the ui plugin registration, you can provide three resources related to styling :
-
:css-resource If there is any, it will be loaded and applied. Here is where you put your JavaFX pluging styles
-
:dark-css-resource This styles are going to be applied only in dark mode
-
:light-css-resource This styles are going to be applied only in light mode
For making sure you plugin styles doesn’t mix with other styles, your plugin is automatically wrapped in a pane with your plugin key (my-plugin in the example above) as a class.
This means your plugin css can contain code like :
.my-plugin .table-view {
-fx-font-family: 'monospaced';
}16. JVM options list
This section only collects the options, search for them in the User’s guide for more context and possible values.
16.1. Clojure and ClojureScript
-
-Dflowstorm.startRecording=false -
-Dflowstorm.plugins.namespaces[.+]=ns1,ns2 -
-Dflowstorm.threadFnCallLimits=org.my-app/fn1:2,org.my-app/fn2:4 -
-Dflowstorm.title=FlowStormMainDebugger -
-Dflowstorm.theme=dark -
-Dflowstorm.styles=~/.flow-storm/big-fonts.css -
-Dflowstorm.fileEditorCommand=emacsclient -n +<<LINE>>:0 <<FILE>> -
-Dflowstorm.jarEditorCommand=emacsclient -n +<<LINE>>:0 <<JAR>>/<<FILE>> -
-Dflowstorm.threadTraceLimit=1000 -
-Dflowstorm.throwOnLimit=true -
-Dflowstorm.autoUpdateUI=false -
-Dflowstorm.callTreeUpdate=false -
-Dflowstorm.uiTimeoutMillis=4000
16.2. Only Clojure
-
-Dclojure.storm.instrumentEnable=true -
-Dclojure.storm.instrumentOnlyPrefixes[.*]=ns-prefix1,ns-prefix2 -
-Dclojure.storm.instrumentAutoPrefixes=false -
-Dclojure.storm.instrumentSkipPrefixes[.*]=my-app.too-heavy,my-lib.uninteresting -
-Dclojure.storm.instrumentSkipRegex=.*test.* -
-Dflowstorm.heapLimit=1000
16.3. Only ClojureScript
-
-Dcljs.storm.instrumentEnable=true -
-Dcljs.storm.instrumentOnlyPrefixes=ns-prefix1,ns-prefix2 -
-Dcljs.storm.instrumentAutoPrefixes=false -
-Dcljs.storm.instrumentSkipPrefixes=my-app.too-heavy,my-lib.uninteresting
17. Styling and theming
All functions that start the debugger ui (flow-storm.api/local-connect, flow-storm.debugger.main/start-debugger) accept a map
with the :styles, :title and :theme keywords. If :styles points to a css file it will be used to overwrite the default styles, in case you
want to change colors, make your fonts bigger, etc. :theme could be one of :auto (default), :light, :dark. Title can be used to
distinguish between multiple debugger instances.
Like this :
user> (local-connect {:styles "~/.flow-storm/big-fonts.css", :theme :dark, :title "FlowStormMainDebugger"})If you are using ClojureStorm you can also provide them with :
-Dflowstorm.title=FlowStormMainDebugger -Dflowstorm.theme=dark -Dflowstorm.styles=~/.flow-storm/big-fonts.css
You can overwrite all the styles defined here https://github.com/flow-storm/flow-storm-debugger/blob/master/resources/flowstorm/styles/styles.css
18. Controlling logging
FlowStorm uses JUL (java.util.logging) as the loggging library.
You can configure JUL logging by starting your repl with -Djava.util.logging.config.file=./logging.properties
If you need to disable logging you can put this in your logging.properties file :
handlers = java.util.logging.ConsoleHandler
flow_storm.level = SEVERE
clojure.storm.level = SEVERE19. Key bindings
19.1. General
-
Ctrl-gCancel any long running task (only search supported yet) -
Ctrl-lClean all debugger state -
Ctrl-dToggle debug-mode. Will log useful debugging information to the console -
Ctrl-uUnblock all breakpoint blocked threads if any -
Ctrl-tRotate themes -
Ctrl-plusIncrement font size -
Ctrl-minusDecrement font size -
F"Select the Flows tool" -
B"Select the Browser tool" -
T"Select the Taps tool" -
D"Select the Docs tool"
19.2. Flows
-
0-9Open focus flow-N threads menu, N being the pressed key -
tSelect the tree tool (needs to be inside a thread) -
cSelect the code tool (needs to be inside a thread) -
fSelect the functions tool (needs to be inside a thread) -
PStep prev over. Go to previous step on the same frame -
pStep prev -
nStep next -
NStep next over. Go to next step on the same frame -
^Step out -
<Step first -
>Step last -
Ctrl-fCopy current function symbol -
Ctrl-Shift-fCopy current function call form -
Ctrl-zUndo navigation -
Ctrl-rRedo navigation
20. Debugging react native applications
Debugging ClojureScript react native application needs a combination of ClojureScript and remote debugging.
Assuming you are using shadow-cljs, have added the flow-storm-inst dependency, and that it started a nrepl server on port 9000, you
can start a debugger and connect to it by running :
clj -Sforce -Sdeps '{:deps {com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}}' -X flow-storm.debugger.main/start-debugger :port 9000 :repl-type :shadow :build-id :your-app-build-id :debugger-host '"YOUR_DEV_MACHINE_IP"'You also need to make it possible for the device to connect back to the debugger on port 7722. You can accomplish this by running :
adb reverse tcp:7722 tcp:7722Also remember that you need to have installed the websocket npm library. You can do this like :
npm install websocket --save21. Working on Windows with WSL2
For those using current versions of WSL2 on Windows it should be pretty straight forward.
-
export DISPLAY=:0
-
export WSL2_GUI_APPS_ENABLED=1
Font issues had been reported on some distros, like java.lang.NullPointerException: Cannot read field "firstFont" because "<local4>" is null which
seams to be solved just by installing font packages like dejavu-fonts or ttf-dejavu depending on the distro.
22. Opening forms in editors
You can add this two jvm options to tell FlowStorm how to open forms in files and inside jars :
-
flowstorm.jarEditorCommand : a command with optional <<JAR>>, <<FILE>> and <<LINE>> placeholders
-
flowstorm.fileEditorCommand : a command with optional <<FILE>> and <<LINE>> placeholders
If you define those, clicking on your forms namespaces link in the code tool should run the provided commands. On expressions sub-forms that contains line meta you should also be able to right click and select "Open in editor" which should open the file at that specific line (useful for long forms).
Here are some known setups for most common editors :
22.1. Emacs
;; for opening your project files
"-Dflowstorm.fileEditorCommand=emacsclient -n +<<LINE>>:0 <<FILE>>"
;; simple way for opening files inside jars (works on linux only)
"-Dflowstorm.jarEditorCommand=emacsclient -n +<<LINE>>:0 <<JAR>>/<<FILE>>"
;; for opening files inside jars that works on every OS (requires FlowStorm >= 3.17.3)
"-Dflowstorm.jarEditorCommand=emacsclient --eval '(let ((b (cider-find-file \"jar:file:<<JAR>>!/<<FILE>>\"))) (with-current-buffer b (switch-to-buffer b) (goto-char (point-min)) (forward-line (1- <<LINE>>))))'"22.2. VSCode
"-Dflowstorm.fileEditorCommand=code --goto <<FILE>>:<<LINE>>"22.3. IntelliJ
"-Dflowstorm.fileEditorCommand=idea --line <<LINE>> <<FILE>>"22.4. Vim
"-Dflowstorm.fileEditorCommand=vim +<<LINE>> <<FILE>>"23. Editors/IDEs integration
23.1. Emacs
Checkout Cider Storm an Emacs Cider front-end with support for Clojure and ClojureScript.
23.2. VSCode
With the following alias setup in deps.edn:
{:aliases {:flowstorm {:classpath-overrides {org.clojure/clojure nil}
:extra-deps {com.github.flow-storm/clojure {:mvn/version "1.13.0-alpha4"}
com.github.flow-storm/flow-storm-dbg {:mvn/version "4.7.0"}}
:jvm-opts ["-Dflowstorm.startRecording=true"
"-Dclojure.storm.intrumentEnable=true"
"-Dclojure.storm.intrumentAutoPrefixes=true"]}}}Create a custom connect sequence in the VSCode settings.json:
{
"name": "flowstorm",
"projectType": "deps.edn",
"cljsType": "none",
"extraNReplMiddleware": ["flow-storm.nrepl.middleware/wrap-flow-storm"],
"afterCLJReplJackInCode": "((requiring-resolve 'flow-storm.storm-api/start-debugger))",
"menuSelections": {
"cljAliases": ["flowstorm"]
}
}Jack-in using the flowstorm sequence from the menu.
25. Known limitations and issues
25.1. Code with macros that don’t preserve meta
FlowStorm works fine with most macros, except the ones that don’t preserve meta at macroexpansion, which FlowStorm needs in their absence, can cause GAPS IN EXECUTION TRACING AND PREVENT IT FROM LINKING THE EXECUTED CODE BACK TO THE ORIGINAL SOURCE.
When macros are involved, the forms compiled by the Clojure compiler aren’t the ones on your source files, but the ones generated by macro-expanding all the macros. In order to link the compiled forms back to the forms in your source code, for each instrumented form, right after the form is read by the reader, FlowStorm will walk the form down, annotating with meta each sub-form with a coordinate, which will then be used after macro expansion to link a compiled expression back to your source code.
Macros can be as simple as code reorganizing ones (like →, when, and, defn, etc) or whole compilers like clojure.core.async/go and
Electric, so it really depends on the macros.
If you see code inside a macro not being traced feel free to report an issue, there is nothing FlowStorm can do from its side but we can work together with the macro developer making sure it preserves all meta after macro expansion, which sometimes may be possible.
25.2. Locals pane and mutable values
The Locals pane will show the value of each binding for a symbol AT BINDING TIME, which is the same thing no matter where you are in the current block when working with immutable objects, BUT NOT WHEN WORKING WITH MUTABLE ONES.
If what was bound was mutable in any way, you will be seeing the value at binding time, and not at current time which could cause some confusion.
25.3. Closed over bindings aren’t displayed in Locals
The locals pane will only display bindings for the current function. Locals visible from the current function but not defined in it (like in the case of closures) aren’t shown.
25.4. Don’t instrument clojure.core or FlowStorm itself
Currently we can’t instrument clojure.core or FlowStorm itself since they endup in infinite tracing recursions. This can be solved, but it is currently a limitation.
25.5. IF test expressions tracing with intrinsics
When you have code like :
(defn foo [^long l]
(if (zero? l)
(+ l 1)
(+ l 2)))because l is a primitive long, the compiler can replace the (zero? l) with intrinsics (LCONST_0, LCMP, IFNE) so the
(zero? l) isn’t a expression anymore, just a statement. In these cases you will see the if test return un-highlighted, but
you can still tell which branch the code went thru because the chosen branch will be the highlighted one.
25.6. Loading an entire file while recording records some weird code
This is because most editors, (specially via nrepl) eval some other code on your namespace in order to load the contents of your file. If that namespace is instrumented this will be also recorded, even when it is probably not of your interest. This is harmless, just clear your recordings before running and recording anything else.
If you follow the best practice of start recording right before running the stuff you are interested in recording you should never see this.
25.7. Macro calls tracing code you don’t see on your code
When you are evaluating some code that macroexpands to a (do form-1 … form-n) the compiler recursively calls eval on the sub forms. Because it is tricky in the compiler to tell apart your original source form from the ones the macroexpansion returned those form-1 to form-n get instrumented and then traced as if they were on your code.
The tricky part is related to tooling like IDEs sometimes wrapping your forms in some macros that expand to a (do form-1 … form-n) so we can’t simply stop instrumenting after that situation.
26. Troubleshooting
26.1. The outputs panel doesn’t work
Checkout that you don’t have piggieback on the classpath dragged by some dependency. Currently if piggieback is pressent FlowStorm will assume a ClojureScript repl in which the outputs panel isn’t supported yet.
26.2. Run with JDK 11
FlowStorm UI requires JDK >= 17. If you can’t upgrade your JDK you can still use it by downgrading JavaFx.
If that is the case add these dependencies to your alias :
org.openjfx/javafx-controls {:mvn/version "19.0.2"}
org.openjfx/javafx-base {:mvn/version "19.0.2"}
org.openjfx/javafx-graphics {:mvn/version "19.0.2"}
org.openjfx/javafx-web {:mvn/version "19.0.2"}27. Internals, diagrams and documentation
For people interested in enhancing, troubleshooting, fixing or just learning about FlowStorm internals take a look at here :
Some useful diagrams :
{kind=link}
{kind=link}
{kind=link}